每当有关 CSS 特异性(以及级联本身)的文章发布时,我都会感到非常兴奋,因为这是语言的核心概念,每个人都应该了解。关于这个主题的文章越多越好!
但是,有时我也会皱一下眉头,因为不幸的是,我有时会遇到一些完全错误的东西。
为了消除一些混淆,这里列出了关于 CSS 特异性的误解…
误解1:特异性是一个十进制分数
一些,通常是老的,文章将特异性表示为十进制分数,或者提到类似类选择器 “增加10个点” 这样的东西。这是不准确的,因为这会意味着具有 “每个1点” 的11个元素选择器将击败只有 “10点” 的1个类选择器。
相反,特异性是一个三元组(或三项),它有三个组成部分:A、B 和 C。A、B 和 C 的值取决于您使用的选择器类型。
A= 类似 ID 的特异性B= 类似类的特异性C= 类似元素的特异性
通常使用 (A,B,C) 表示它。例如:(1,0,2)。也经常使用 A-B-C 表示法。
🤓 我写了一个可以计算选择器特异性的 JavaScript 库:@bramus/specificity。它驱动着这个交互式特异性计算器。
特异性通过按顺序比较三个组件进行比较:具有较大 A 值的特异性更具体;如果两个 A 值相等,则具有较大 B 值的特异性更具体;如果两个 B 值也相等,则具有较大 C 值的特异性更具体;如果所有值都相等,则两个特异性相等。
在代码中,它看起来像这样:
const compare = (s1, s2) => {
if (s1.a === s2.a) {
if (s1.b === s2.b) {
return s1.c - s2.c;
}
return s1.b - s2.b;
}
return s1.a - s2.a;
};
例如,(1,0,0) 比 (0,10,3) 的特异性更高,因为 (1,0,0) 中的 A 值(即 1)大于 (0,10,3) 中的 A 值(即 0)。
还请参阅我的有关级联的 CSS Day 2022 讲座摘录:
关于级联的 CSS Day 讲座摘录,涵盖了如何编写和比较特异性
💡 虽然您可以通过添加足够多的前导零将三元组表示为十进制数,但它 带来了自己的一套挑战:您最终得到的数字难以阅读/解析 + 您需要添加“足够多”的零以获得正确可排序的结果。
我的建议仍然是:不要这样做。
混淆源自:
回到 CSS 选择器 3,规范提到,您可以将数字串联起来以获得特异性。
将三个数字 a-b-c(在一个大的基数数系统中)连接起来得到特异性。
虽然有“在一个大的基数数系统中”的警告,但这个条款被忽视了,很可能是因为规范示例中显示了十进制的示例,例如 #s12:not(FOO) /* a=1 b=0 c=1 -> specificity = 101 */。
将近15年过去了,我们仍然困在其中:一些作者继续使用十进制表示特异性,因为这样“更容易解释”。虽然这可能是正确的,但这教给人们的是错误的东西。让他们以后再学习是非常困难的。
误解2:使用 style 属性会增加特异性
我经常看到使用 style 属性 “增加1000点特异性” 这样的说法。这是不正确的,因为 style 属性的评估是级联的一个较早步骤 —— 它与特异性毫不相干。
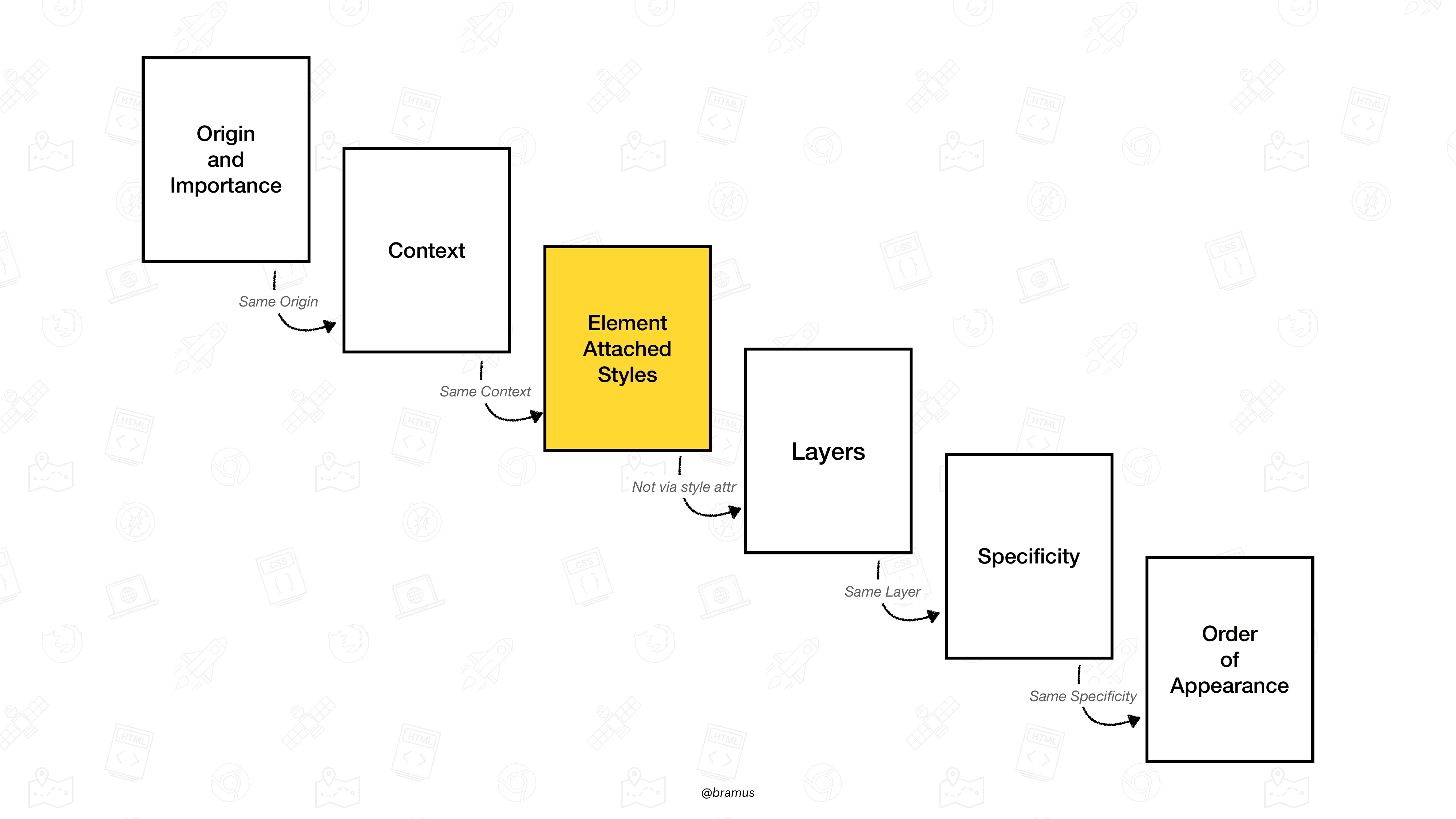
级联的各个步骤(根据 CSS Cascade 5),突出显示了 style 属性
混
淆源自:
回到 CSS2 时代 (在 2011 年),事实上是这样的。在那个规范中,特异性是四元组 (A,B,C,D),其中 style 属性是 A 组件。
但自从 CSS3 以后,情况不再如此。
误解3:使用 !important 会增加特异性
我经常看到在声明中添加 !important 会 “增加10000点特异性” 这样的说法。这是不正确的,因为 使用 !important 将声明放置在不同的来源 中。通过在您的作者样式中使用 !important,声明将从 Normal Author Declarations 来源移动到 Important Author Declarations 来源。
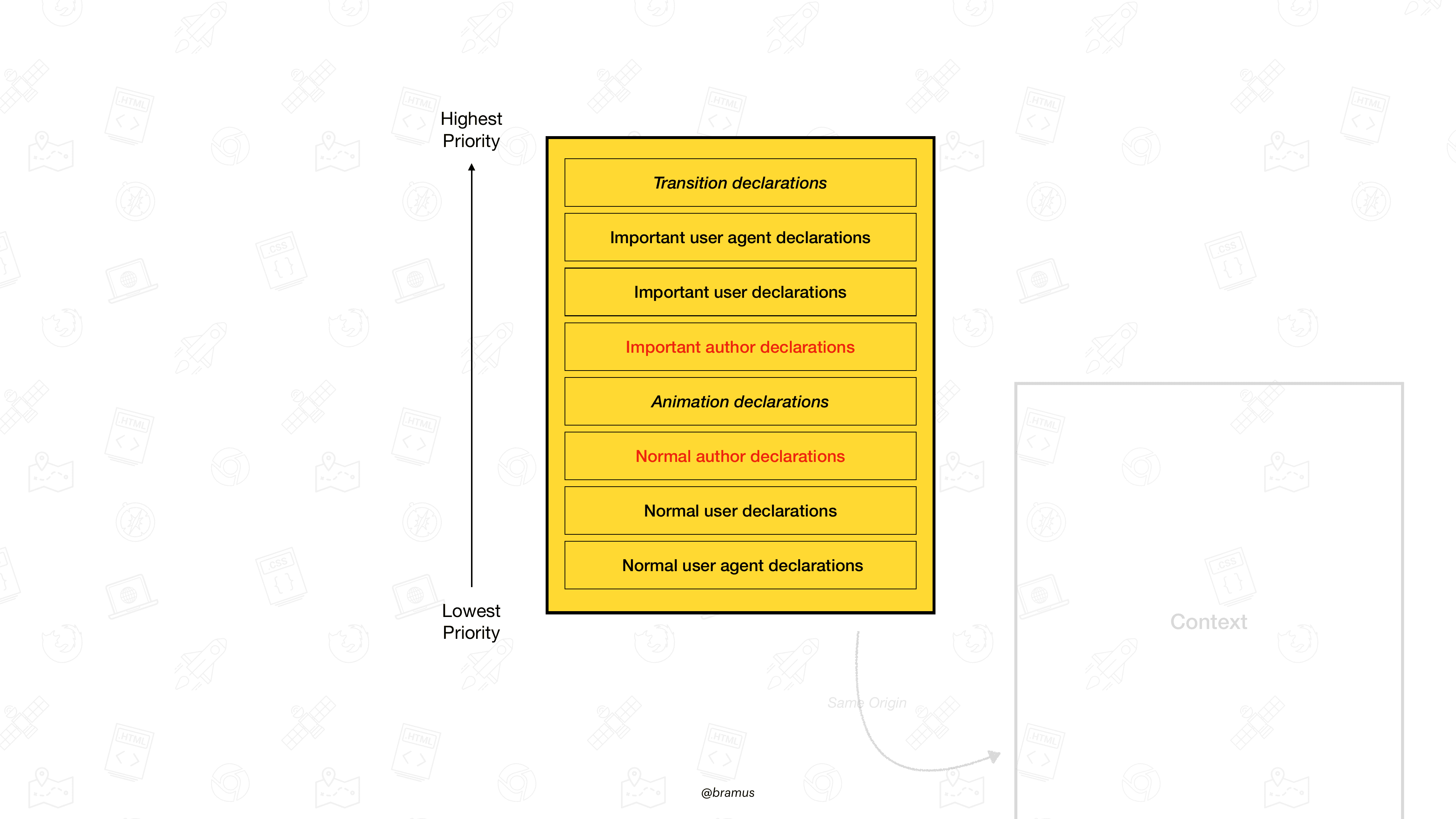
各种来源(根据 CSS Cascade 5),突出显示了普通作者声明和重要作者声明
来源和重要性是级联的第一个检查标准。特异性要远远晚些时候才会涉及。
混淆源自:
我在规范中找不到任何硬迹象,但我猜想这是 在特异性直接遵循来源标准时某人提出的。那种简化当时是有道理的,但现在不再有道理了,因为它跳过了在来源+重要性和特异性之间的三个额外级联标准:上下文、元素附加样式和层级。