React 的核心架构一遍又一遍地调用你给它的函数(即你的组件)。这一事实既通过简化其心智模型促成了它的流行,也创造了可能出现性能问题的地方。一般来说,如果你的函数执行昂贵的操作,那么你的应用程序将会变慢。
因此,性能调整成为了开发者的痛苦点,因为他们必须手动告诉 React 哪些函数应该重新运行以及何时运行。React 团队现在提供了一个名为 React 编译器的工具,通过重写他们的代码来自动化开发者的手动性能调整工作。
React 编译器对你的代码做了什么?它在内部是如何工作的?你应该使用它吗?让我们深入了解。
要通过深入研究其内部结构来获得对 React 的完整、准确的心智模型,请查看我的新课程 理解 React,我们将深入挖掘 React 的源代码。我发现深入理解 React 的内部结构对即使是有多年 React 经验的开发者也有很大帮助。
编译器、转译器和优化器
我们听到编译器、转译器和优化器这些术语在现代 JavaScript 生态系统中被随意使用。它们是什么?
转译
转译器是一个程序,它分析你的代码并输出功能等价的代码,使用不同的编程语言,或者是你代码的调整版本,使用相同的编程语言。
React 开发者多年来一直在使用转译器将 JSX 转换为实际由 JavaScript 引擎运行的代码。JSX 本质上是构建嵌套函数调用树的简写(然后构建嵌套对象树)。
编写嵌套函数调用是繁琐且容易出错的,所以 JSX 使开发者的生活更轻松,需要一个转译器来分析 JSX 并将其转换为这些函数调用。
例如,如果你使用 JSX 编写了以下 React 代码:
注意,为了便于阅读,本博客文章中的所有代码都故意过度简化。
function App() {
return <Item item={item} />;
}
function Item({ item }) {
return (
<ul>
<li>{ item.desc }</li>
</ul>
)
}
经过转译后,它变成了:
function App() {
return _jsx(Item, {
item: item
});
}
function Item({ item }) {
return _jsx("ul", {
children: _jsx("li", {
children: item.desc
})
});
}
这是实际发送到浏览器的代码。不是类似 HTML 的语法,而是传递纯 JavaScript 对象的嵌套函数调用,React 称之为“props”。
转译的结果展示了为什么你不能在 JSX 中轻易使用 if 语句。你不能在函数调用内部使用 if 语句。
你可以快速生成并检查转译 JSX 的输出,使用 Babel。
编译和优化
那么,转译器和编译器有什么区别呢?这取决于你问的是谁,以及他们的教育和经验是什么。如果你来自计算机科学背景,你可能主要接触到编译器作为一个程序,将你编写的代码转换为机器语言(处理器实际理解的二进制代码)。
然而,“转译器”也被称为“源到源编译器”。优化器也被称为“优化编译器”。转译器和优化器是编译器的类型!
命名事物很难,所以对于什么构成转译器、编译器或优化器会有分歧。重要的是要理解,转译器、编译器和优化器是程序,它们获取包含你代码的文本文件,分析它,并生成不同但功能等价的新文本文件。它们可以使你的代码更好,或者通过调用其他人的代码来添加它之前没有的能力。
编译器、转译器和优化器是获取包含你代码的文本文件,分析它,并生成不同但功能等价的代码的程序。
React 编译器最后做的就是这个。它创建了功能上等同于你编写的代码,但是通过调用 React 团队编写的代码来包装它的一部分。这样,你的代码被重写为做你打算做的事情,再加上更多。我们一会儿会看到“更多”是什么。
抽象语法树
当我们说你的代码被“分析”时,我们指的是你的代码文本逐个字符地被解析,算法对它运行以找出如何调整它、重写它、添加功能等。解析通常会产生一个抽象语法树(或 AST)。
虽然这听起来很花哨,但它实际上只是代表你的代码的树形数据结构。然后,分析这棵树比分析你编写的代码更容易。
例如,假设你的代码中有这样一行:
const item = { id: 0, desc: 'Hi' };
那行代码的抽象语法树最终可能看起来像这样:
{
type: VariableDeclarator,
id: {
type: Identifier,
name: Item
},
init: {
type: ObjectExpression,
properties: [
{
type: ObjectProperty,
key: id,
value: 0
},
{
type: ObjectProperty,
key: desc,
value: 'Hi'
}
]
}
}
生成的数据结构描述了你编写的代码,将其分解成包含类型和任何相关值的小定义片段。例如 desc: 'Hi' 是一个 ObjectProperty,有一个叫做 'desc' 的 key 和一个值为 'Hi' 的 value。
这是你在想象转译器/编译器等对你的代码做了什么时应该拥有的心智模型。人们编写了一个程序,它获取你的代码(文本本身),将其转换为数据结构,并对它进行分析和工作。
最终生成的代码也来自这个 AST,也许还有一些其他的中间语言。你可以想象遍历这个数据结构并输出文本(同一语言或不同语言的新代码,或者以某种方式调整它)。
在 React 编译器的情况下,它同时使用 AST 和中间语言从你编写的代码生成新的 React 代码。需要记住的是,React 编译器和 React 本身一样,只是《其他人的代码》。
当谈到编译器、转译器、优化器等时,不要把这些工具想成神秘的黑匣子。把它们想成如果你有时间,你也可以构建的东西。
React 的核心架构
在我们继续讨论 React 编译器本身之前,还有一些概念需要明确。
记得我们说过 React 的核心架构既是其流行的来源,也是潜在的性能问题吗?我们看到当你写 JSX 时,你实际上正在写嵌套函数调用。但你正在把你的函数交给 React,它将决定何时调用它们。
让我们以一个处理大量项目的 React 应用程序的开始为例。假设我们的 App 函数获取了一些项目,我们的 List 函数处理并显示它们。
function App() {
// TODO: 在这里获取一些项目
return <List items={items} />;
}
function List({ items }) {
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
}
我们的函数返回纯 JavaScript 对象,比如 ul 对象,它包含它的子项(这里最终将是多个 li 对象)。这些对象中的一些,如 ul 和 li,是 React 内置的。其他的是我们创建的,比如 List。
最终,React 将从所有这些对象构建一棵树,称为 Fiber 树。树中的每个节点称为 Fiber 或 Fiber 节点。创建我们自己的 JavaScript 对象树来描述 UI 的想法称为创建“虚拟 DOM”。
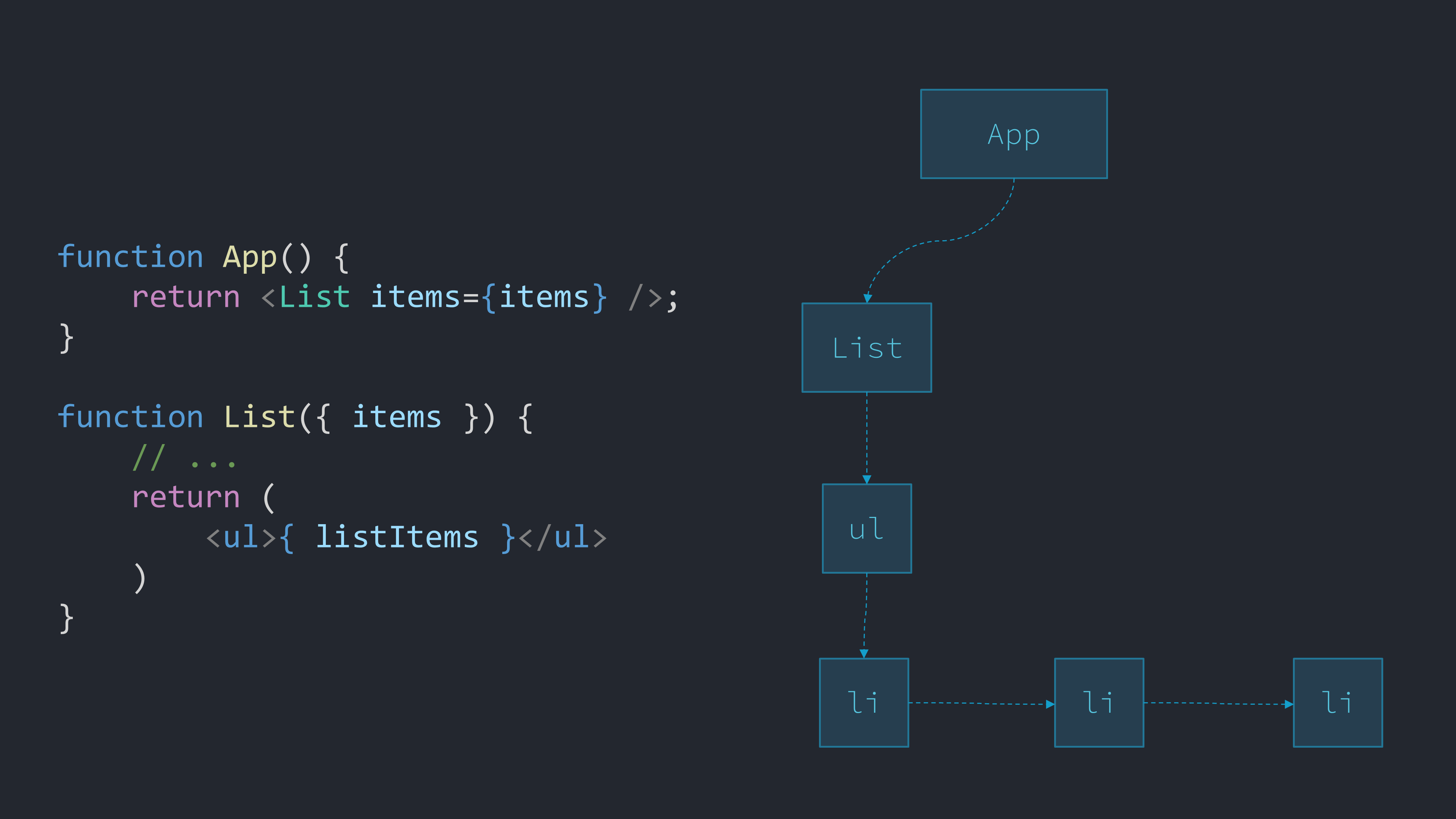
React 实际上在树的每个节点上保持两个分支,它们可以分叉。一个分支称为“当前”状态的分支(与 DOM 匹配),另一个是树的“进行中”状态的分支,它与我们的函数重新运行时创建的树匹配。
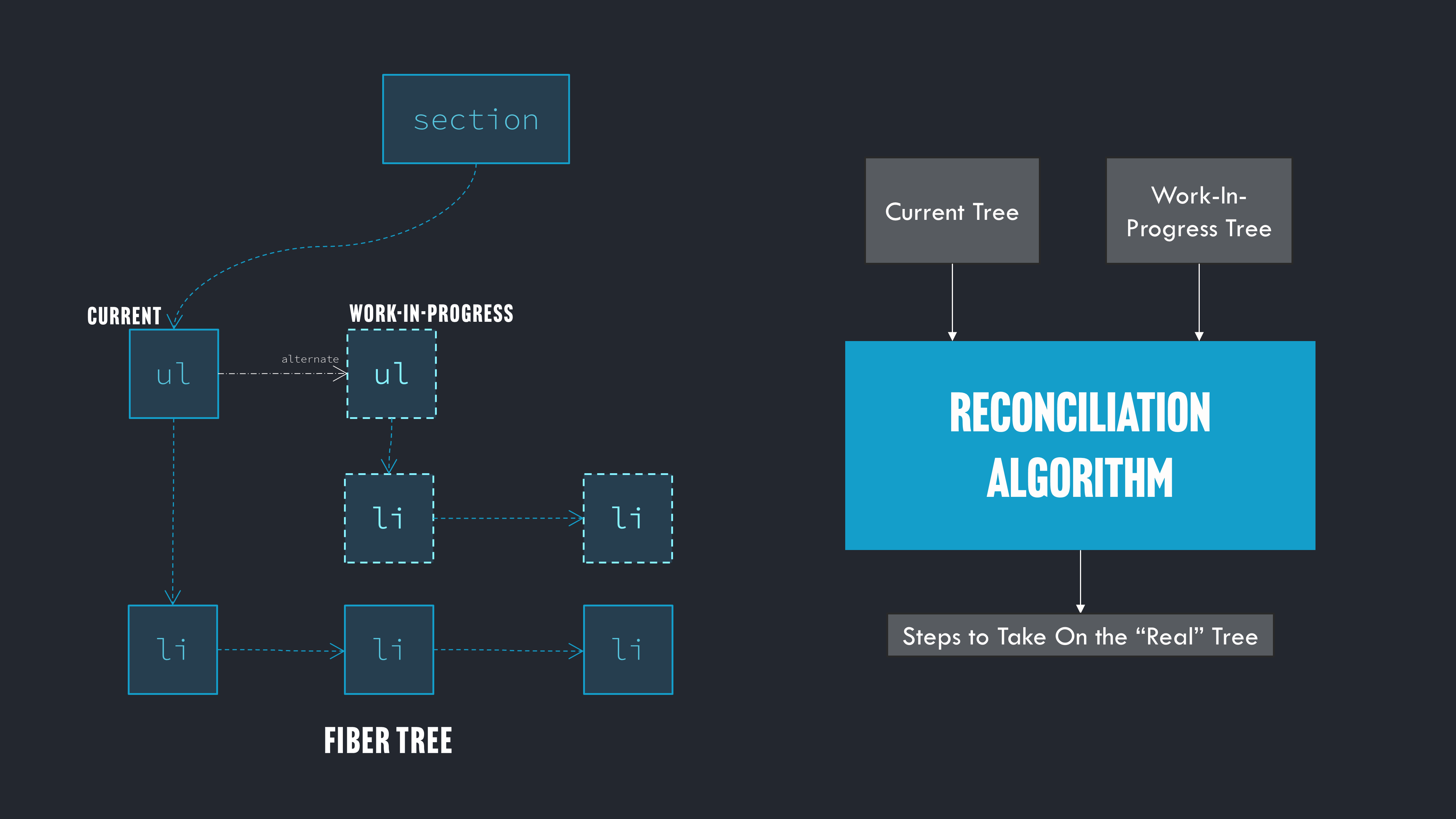
然后,React 将比较这两棵树,以决定需要对实际 DOM 进行哪些更改,以便 DOM 与进行中的树的一侧匹配。这个过程称为“调和”。
因此,根据我们向应用程序添加的其他功能,React 可能会选择一遍又一遍地调用我们的 List 函数,每当它认为 UI 可能需要更新时。这使得我们的心智模型相当直接。每当 UI 可能需要更新时(例如,作为对用户操作的响应,如点击按钮),定义 UI 的函数将再次被调用,React 将弄清楚如何更新实际的浏览器 DOM,以匹配我们的函数所说的 UI 应该看起来如何。
但如果 processItems 函数很慢,那么每次调用 List 都会很慢,我们的整个应用程序在交互时都会变慢!
记忆化
解决对昂贵函数的重复调用的编程解决方案是缓存函数的结果。这个过程称为记忆化。
要使记忆化起作用,函数必须是“纯”的。这意味着如果你传递相同的输入到函数中,你总是得到相同的输出。如果真是这样,那么你可以采取输出并以一种与输入集相关的方式存储它。
下次你调用昂贵的函数时,我们可以编写代码来查看输入,检查缓存,看看我们是否已经用这些输入运行过该函数,如果是,那么从缓存中获取存储的输出,而不是再次调用该函数。没有必要再次调用该函数,因为我们知道输出将与上次使用这些输入时相同。
如果之前使用的 processItems 函数实现了记忆化,它可能看起来像这样:
function processItems(items) {
const memOutput = getItemsOutput(items);
if (memOutput) {
return memOutput;
} else {
// ...运行昂贵的处理
saveItemsOutput(items, output);
return output;
}
}
我们可以想象 saveItemsOutput 函数存储一个对象,保存项目和函数的关联输出。getItemsOutput 将查看 items 是否已经存储,如果是,我们将返回相关的缓存输出,而不需要再做更多的工作。
对于 React 一遍又一遍调用函数的架构,记忆化成为帮助保持应用程序不慢下来的关键技术。
钩子存储
为了理解 React 编译器,还有一部分 React 架构需要理解。
React 会再次调用你的函数,如果应用程序的“状态”发生变化,这意味着创建 UI 所依赖的数据。例如,一个数据片段可能是“showButton”,它是 true 或 false,UI 应该根据该数据的值显示或隐藏按钮。
React 在客户端设备上存储状态。怎么做?让我们以将呈现并与项目列表交互的 React 应用程序为例。假设我们最终将存储一个选定的项目,客户端处理项目以呈现,处理事件,并排序列表。我们的应用程序可能开始看起来像下面这样。
function App() {
// TODO: 在这里获取一些项目
return <List items={items} />;
}
function List({ items }) {
const [selItem, setSelItem] = useState(null);
const [itemEvent, dispatcher] = useReducer(reducer, {});
const [sort, setSort] = useState(0);
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
}
当 useState 和 useReducer 行由 JavaScript 引擎执行时,真正发生了什么?从我们的 List 组件创建的 Fiber 树节点有一些额外的 JavaScript 对象附加到它上面,用于存储我们的数据。这些对象中的每一个都连接到一个称为链表的数据结构中。
顺便说一下,很多开发者认为 useState 是 React 中状态管理的核心单元。但它不是!它实际上是对 useReducer 的一个简单调用的包装。

所以,当你调用 useState 和 useReducer 时,React 会将状态附加到 Fiber 树,它在我们应用程序运行时一直存在。因此,状态作为我们的函数不断重新运行时仍然可用。
钩子的存储方式也解释了“钩子规则”,你不能在循环或 if 语句中调用钩子。每次你调用钩子时,React 都会移动到链表中的下一项。因此,你调用钩子的次数必须是一致的,否则 React 有时会指向链表中的错误项。
最终,钩子只是设计用来在用户设备内存中保存数据(和函数)的对象。这是理解 React 编译器真正做了什么的关键。但还有更多。
React 中的记忆化
React 结合了记忆化和它对钩子存储的理念。你可以记忆化你给 React 的整个函数的结果,它们是 Fiber 树(如 List)的一部分,或者在它们内部调用的单个函数(如 processItems)。
缓存存储在哪里?在 Fiber 树中,就像状态一样!例如,useMemo 钩子在调用 useMemo 的节点上存储输入和输出。
所以,React 已经有了在作为 Fiber 树一部分的 JavaScript 对象的链表中存储昂贵函数结果的想法。这很好,除了一件事:维护。
在 React 中,记忆化可能是繁琐的,因为你必须明确告诉 React 记忆化依赖于哪些输入。我们对 processItems 的调用变成了:
const pItems = useMemo(processItems(items), [items]);
在末尾的数组是“依赖项”列表,即输入,如果它们改变,告诉 React 应该再次调用该函数。你必须确保你正确地得到了这些输入,否则记忆化将无法正常工作。跟上这些输入变成了一项文书工作。
React 编译器
进入 React 编译器。一个程序,它分析你的 React 代码的文本,并生成新的代码,准备进行 JSX 转译。但那个新代码有一些额外的东西被添加了。
让我们看看 React 编译器对我们的应用程序在这个案例中做了什么。编译之前它是:
function App() {
// TODO: 在这里获取一些项目
return <List items={items} />;
}
function List({ items }) {
const [selItem, setSelItem] = useState(null);
const [itemEvent, dispatcher] = useReducer(reducer, {});
const [sort, setSort] = useState(0);
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
}
编译后它变成了:
function App() {
const $ = _c(1);
let t0;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t0 = <List items={items} />;
$[0] = t0;
} else {
t0 = $[0];
}
return t0;
}
function List(t0) {
const $ = _c(6);
const { items } = t0;
useState(null);
let t1;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t1 = {};
$[0] = t1;
} else {
t1 = $[0];
}
useReducer(reducer, t1);
useState(0);
let t2;
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}
const listItems = t2;
let t3;
if ($[4] !== listItems) {
t3 = <ul>{listItems}</ul>;
$[4] = listItems;
$[5] = t3;
} else {
t3 = $[5];
}
return t3;
}
这是很多!让我们分解一下现在重写的 List 函数,以理解它。
它开始于:
const $ = _c(6);
那个 _c 函数(认为“c”代表“缓存”)创建了一个数组,使用钩子存储。React 编译器分析了我们的 Link 函数,并决定,为了最大限度地提高性能,我们需要存储六件事。当我们的函数第一次被调用时,它在那个数组中存储了这六件事的每个结果。
是我们函数后续调用中缓存的作用。例如,只看我们调用 processItems 的区域:
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}
围绕 processItems 的整个工作,包括调用函数和生成 li,都被包装在一个检查中,看数组第二位的缓存($[1])是否与函数上次被调用时的相同输入相同(传递给 List 的 items 的值)。
如果它们相等,那么缓存数组第三位($[2])被使用。它存储了当 items 被映射时生成的所有 li 的列表。React 编译器的代码说,“如果你给我和上次调用这个函数时相同的项目列表,我会给你我上次缓存的 li 列表。”
如果传递的 items 不同,那么它调用 processItems。即使在那时,它也使用缓存来存储一个列表项看起来像什么。
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}
看到 t3 = 那一行了吗?而不是重新创建返回 li 的箭头函数,它将 函数本身 存储在缓存数组的第四位($[3])。这节省了 JavaScript 引擎在下次调用 List 时创建那个小函数的工作。由于那个函数永远不会改变,最初的 if 语句基本上是在说“如果缓存数组的这个位置是空的,就缓存它,否则从缓存中获取。”
通过这种方式,React 自动缓存值并记忆化函数调用的结果。它输出的代码在功能上等同于我们编写的代码,但包括了缓存这些值的代码,节省了我们的函数被 React 一遍又一遍调用时的性能损失。
React 编译器虽然在比开发者通常使用记忆化更细粒度的级别上进行缓存,并且是自动进行的。这意味着开发者不需要手动管理依赖项或记忆化。他们可以只编写代码,React 编译器将从它生成的新代码中利用缓存使其更快。
值得一提的是,React 编译器仍在生成 JSX。实际运行的代码是 JSX 转译后 React 编译器的结果。
在 JavaScript 引擎中实际运行的 List 函数(发送到浏览器或服务器)看起来像这样:
function List(t0) {
const $ = _c(6);
const {
items
} = t0;
useState(null);
let t1;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t1 = {};
$[0] = t1;
} else {
t1 = $[0];
}
useReducer(reducer, t1);
useState(0);
let t2;
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = item => _jsx("li", {
children: item
});
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}
const listItems = t2;
let t3;
if ($[4] !== listItems) {
t3 = _jsx("ul", {
children: listItems
});
$[4] = listItems;
$[5] = t3;
} else {
t3 = $[5];
}
return t3;
}
React 编译器添加了一个用于缓存值的数组,以及所有需要的 if 语句。JSX 转译器将 JSX 转换为嵌套函数调用。你编写的和你实际运行的 JavaScript 引擎之间的差异并不小。我们信任其他人的代码来产生符合我们最初意图的东西。
用处理器周期交换设备内存
一般来说,记忆化和缓存意味着用处理器周期来交换内存。你节省了处理器执行昂贵操作的开销,但是你通过在内存中存储东西来避免这种情况。
如果你使用 React 编译器,这意味着你在说“尽可能多地存储”在设备内存中。如果代码在用户的设备上的浏览器中运行,这是一个需要记住的架构考虑。
对于许多 React 应用程序来说,这可能不会是一个真正的问题。但是,如果你的应用程序中处理大量数据,那么设备内存使用是你应该至少意识到并在使用 React 编译器时注意的事情,一旦它离开了实验阶段。
抽象和调试
编译的所有形式都相当于在你编写的代码和实际运行的代码之间的抽象层。
正如我们所看到的,在 React 编译器的情况下,要理解实际发送到浏览器的内容,你需要将你的代码通过 React 编译器运行,然后 将那个 代码通过 JSX 转译器运行。
向我们的代码添加抽象层有一个缺点。它们可能使我们的代码更难调试。这并不意味着我们不应该使用它们。但是你应该清楚地记住,你需要调试的代码不仅仅是你的,还有工具生成的代码。
在抽象层生成的代码中进行调试的真正区别在于,对抽象有一个准确的心智模型。完全理解 React 编译器的工作原理将使你能够调试它编写的代码,提高你的开发体验,降低你的开发生活压力。