在前端开发的世界里,有一件事是确定的:变化是唯一的不变。新框架不断涌现,而库也可能在没有警告的情况下变得过时。跟上不断变化的生态系统需要处理各种大小的代码转换。对我们来说,一个重大转变是从Enzyme过渡到React Testing Library (RTL),这促使许多工程师将他们的测试代码转换为更注重用户的RTL方法。尽管Enzyme和RTL各有优缺点,但Enzyme不支持React 18的情况给我们提供了一个令人信服的理由去转向RTL。这个理由如此有力,以至于我们在Slack决定将超过15000个前端单元和集成Enzyme测试转换为RTL,作为更新到React 18的一部分。
我们首先探索了寻找React 18的潜在Enzyme适配器的最简单途径。不幸的是,我们的搜索没有找到可行的选项。在他题为“Enzyme is dead. Now what?”的文章中,React 17适配器的作者Wojciech Maj明确建议:“你现在应该考虑寻找Enzyme的替代品。”

适配器展示了React 18和Enzyme的不匹配和不兼容
考虑到我们最终的目标是更新到Enzyme不支持的React 18,我们首先对问题的范围进行了彻底的分析,并探索了自动化此过程的方法。我们的计划开始于将超过15000个Enzyme测试用例转换的巨大任务,这相当于超过10000个潜在的工程小时。在如此规模下,需要这么多工程时间,优化和自动化这一过程几乎是必须的。尽管我们对现有工具进行了彻底审查并进行了广泛的Google搜索,我们并没有找到适合这个非常常见问题的解决方案。在这篇博客中,我将向您介绍我们自动化Enzyme到RTL转换过程的方法。它包括分析和确定挑战的范围,独立利用传统的抽象语法树(AST)转换和AI大语言模型(LLM),然后是我们结合AST和LLM方法的自定义混合方法。
抽象语法树(AST)转换
我们最初的方法集中在一个更传统的自动代码转换方式——抽象语法树(AST)转换。这些转换使我们能够将代码表示为带有节点的树结构,并创建从一个代码节点到另一个代码节点的目标查询。例如,wrapper.find('selector'); 可以表示为:

`wrapper.find(‘selector’);`的AST表示
自然地,我们希望创建规则来解决最常见的转换模式。除了专注于渲染方法,如mount和shallow,以及利用它们的各种助手函数,我们还确定了最常用的Enzyme方法,以优先考虑转换工作。这是我们代码库中前10种方法:
[
{ method: 'find', count: 13244 },
{ method: 'prop', count: 3050 },
{ method: 'simulate', count: 2755 },
{ method: 'text', count: 2181 },
{ method: 'update', count: 2147 },
{ method: 'instance', count: 1549 },
{ method: 'props', count: 1522 },
{ method: 'hostNodes', count: 1477 },
{ method: 'exists', count: 1174 },
{ method: 'first', count: 684 },
... 还有55种其他方法
]
我们转换的一个重要要求是实现100%的正确转换,因为任何偏差都会导致不正确的代码生成。这个挑战在AST转换中尤为突出,要创建100%准确的转换,我们需要为每种场景手动创建高度具体的规则。在我们的代码库中,我们发现了65种Enzyme方法,每种都有其独特性,这导致了快速扩展的规则集和对我们努力可行性的不断增加的担忧。
例如,Enzyme方法find接受多种参数,如选择器字符串、组件类型、构造函数和对象属性。它还支持像first或filter这样的嵌套过滤方法,提供了强大的元素定位能力,但也增加了AST操作的复杂性。
除了方法转换所需的大量手动规则外,某些逻辑依赖于渲染组件的文档对象模型(DOM),而不仅仅是RTL中是否存在可比较的方法。例如,getByRole和getByTestId之间的选择取决于渲染组件中存在的可访问性角色或测试ID。然而,AST缺乏包含此类上下文信息的能力。其功能仅限于基于正在转换的文件内容处理转换逻辑,而不考虑外部来源,如实际DOM或React组件代码。
随着我们处理每个新转换规则,难度似乎在不断增加。在为10种Enzyme方法建立模式并解决与我们自定义的Jest匹配器和查询选择器相关的其他明显模式之后,很明显,仅靠AST无法处理这个转换任务的复杂性。因此,我们采用了一种务实的方法:对于最常见的情况,我们实现了相对满意的转换,而对于更复杂的情况,我们则进行手动干预。对于每行需要手动调整的代码,我们添加了带有建议和相关文档链接的注释。这种混合方法在所选评估文件中产生了45%的自动转换代码的适度成功率。最终,我们决定将这个工具提供给我们的前端开发团队,建议他们首先运行我们的基于AST的codemod,然后手动处理剩余的转换。
探索AST提供了对问题复杂性的有用见解。我们面临的是Enzyme和RTL中不同的测试方法之间没有直接映射的挑战。此外,没有合适的工具可以有效地自动化这一过程。因此,我们不得不寻找替代方法来解决这个挑战。
大语言模型(LLM)转换

团队成员热情讨论AI应用
在广泛讨论AI解决方案及其在行业中的潜在应用时,我们的团队感到有必要探索它们在我们自身挑战中的适用性。与Slack的DevXP AI团队合作,他们专注于将AI整合到开发者体验中,我们将Anthropic的AI模型Claude 2.1的能力集成到我们的工作流程中。我们创建了提示,并将测试代码与这些提示一起发送到我们最近实现的API端点。
尽管我们尽了最大努力,但我们遇到了显著的变化和不一致性。转换成功率在40-60%之间波动。结果从极其有效的转换到令人失望的不足不一,这在很大程度上取决于任务的复杂性。虽然有些转换表现出色,特别是在将高度特定于Enzyme的方法转换为功能性RTL等价物时,但我们尝试精炼提示的努力效果有限。我们的提示微调尝试可能使问题复杂化,可能使AI模型感到困惑而不是帮助它。任务的范围过于庞大和多方面,因此单独应用AI未能提供我们所寻求的一致结果,突显了我们转换任务的复杂性。
我们不得不依靠手动转换,自动化程度较低的现实令人沮丧。这意味着要将我们团队和公司大量的时间投入到测试迁移上,这些时间本可以用来为我们的客户开发新功能或提升开发者体验。然而,在Slack,我们非常重视创造力和工艺,因此我们并没有就此停止努力。相反,我们仍然决心探索每一个可能的途径。
AST + LLM转换
我们决定观察人类如何进行测试转换,并找出我们可能忽略的任何方面。在手动人类转换和自动化过程之间的比较中,一个显著的优势是人类在转换任务期间可访问的丰富信息。在转换过程中,人类受益于从各种来源获取的宝贵见解,包括渲染的React组件DOM、React组件代码(通常由同一人编写)、AST转换和对前端技术的广泛经验。认识到这一点的重要性,我们审查了我们的工作流程,并将大部分相关信息整合到我们的转换管道中。这是我们最终的管道流程图:
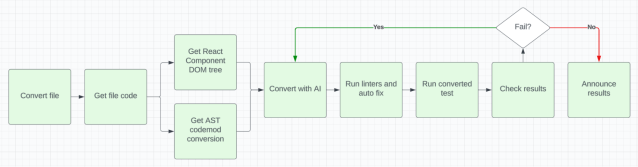
项目管道流程图
这种战略转变,以及AST和AI技术的整合,帮助我们实现了基于所选文件的80%转换成功率,展示了这些方法的互补性及其在解决我们所面临挑战时的综合效力。
在优化我们的转换过程的追求中,我们实施了几项战略决策,使我们的LLM模型
更加高效。我们对示例的选择进行了仔细审查,只包括必要的样本,而不是将所有单元测试和集成测试文件发送给模型。随着时间的推移,我们在向提示中包含这些示例方面变得更加熟练,增强了模型的上下文理解能力。
我们还对不兼容的部分进行了修改。我们会首先通过AST转换,然后对无法完全处理的复杂转换创建注释。这些注释会被发送给AI模型,让其在现有转换之上进行改进。我们通过对代码上下文、React组件文件和渲染DOM的适当提示补充,克服了之前面临的挑战,显著提高了AI模型在适当转换代码中的准确性。
更重要的是,我们在几个阶段对转换进行了验证,包括通过端到端测试、应用程序测试和质量工程评估。这些措施确保了生成代码的准确性和功能完整性。通过这种全面的方法,我们能够有效地提高转换的成功率,使我们的项目向前推进。
成功的催化剂
AST和LLM的结合为我们提供了一个独特而强大的解决方案,显著提高了我们的转换效率,减少了需要手动处理的代码量。凭借这两个领域的优势,我们创建了一个强大的工具集,不仅节省了时间,还增强了转换代码的准确性和一致性。
然而,这种结合不仅仅是技术上的胜利。它还展示了团队合作和创造力的力量。我们在Slack的工程团队展示了韧性、适应力和对创新的承诺。面对复杂的挑战,我们通过整合技术和集体智慧,创造出一个能够处理复杂转换任务的解决方案。
通过这种体验,我们不仅成功地将我们的测试代码从Enzyme迁移到React Testing Library,还在如何高效应对和克服开发挑战上积累了宝贵的知识。我们的旅程展示了在不断发展的前端开发领域,灵活性和创新力是取得成功的关键。模型提供了实现更准确和相关转换所必需的上下文信息。
这个收集步骤至关重要,因为每个测试用例可能有不同的设置和传递给组件的属性,导致每个测试用例的 DOM 结构不同。作为我们管道的一部分,我们运行了 Enzyme 测试并提取了呈现的 DOM。为了简化这个过程,我们为 Enzyme 渲染方法开发了适配器,并将每个测试用例的呈现 DOM 存储在 LLM 模型可消费的格式中。例如:
// 导入原始方法
import enzyme, { mount as originalMount, shallow as originalShallow } from 'enzyme';
import fs from 'fs';
let currentTestCaseName: string | null = null;
beforeEach(() => {
// 在每个测试之前设置当前测试用例名称
const testName = expect.getState().currentTestName;
currentTestCaseName = testName ? testName.trim() : null;
});
afterEach(() => {
// 在每个测试之后重置当前测试用例名称
currentTestCaseName = null;
});
// 覆盖 mount 方法
enzyme.mount = (node: React.ReactElement, options?: enzyme.MountRendererProps) => {
const wrapper = originalMount(node, options);
const htmlContent = wrapper.html();
if (process.env.DOM_TREE_FILE) {
fs.appendFileSync(
process.env.DOM_TREE_FILE,
`<test_case_title>${currentTestCaseName}</test_case_title> and <dom_tree>${htmlContent}</dom_tree>;\n`,
);
}
return wrapper;
};
...
使用提示和 AST 控制 LLM
我们必须整合的第二个创造性变化是对我们 LLM 的幻觉和不稳定响应的更强大和严格的控制机制。我们通过两种关键机制实现了这一点:提示和用 AST codemod 制作的代码内指令。通过这些方法的战略组合,我们创建了一个更加连贯和可靠的转换过程,确保了我们 AI 驱动的转换的准确性和一致性。
我们最初将提示作为指导 LLM 模型的主要手段进行了实验。然而,这被证明是一项耗时的任务。我们尝试为所有请求,包括初始请求和反馈请求,创建一个通用提示,但遇到了挑战。虽然我们本可以通过使用一个单一的、全面的提示来压缩我们的代码,但发现这种方法导致向 LLM 提出的请求复杂性显著增加。相反,我们选择通过制定包含三个部分的关键指令的提示来简化流程:介绍和一般上下文设置,主要请求(10 项明确的必需任务和七项可选任务),其次是如何评估和呈现结果的指示:
上下文设置:
`我需要帮助将 Enzyme 测试用例转换为 React Testing Library 框架。
我将在 <code></code> xml 标签内提供 Enzyme 测试文件代码。
我还将提供部分转换的测试文件代码在 <codemod></codemod> xml 标签内。
每个测试用例的呈现组件 DOM 树将在 <component></component> 标签内提供,具有这种结构的一个或多个测试用例为 "<test_case_title></test_case_title> 和 <dom_tree></dom_tree>"。`
主要请求:
`请执行以下任务:
1. 完成 <codemod></codemod> 标签内测试文件的转换。
2. 转换所有测试用例,并确保文件中测试数量相同。${numTestCasesString}
3. 将 Enzyme 方法替换为等效的 React Testing Library 方法。
4. 更新 Enzyme 导入到 React Testing Library 导入。
5. 调整 Jest 匹配器以适应 React Testing Library。
6. 返回所有转换测试用例的整个文件,用 <code></code> 标签包围。
7. 不要修改其他任何内容,包括 React 组件和助手的导入。
8. 保留所有抽象函数的原样,并在转换后的文件中使用它们。
9. 保持 describe 和 it 块的原始组织和命名。
10. 将组件渲染包装在 <Provider store={createTestStore()}><Component></Provider> 中。为了做到这一点,你需要做两件事
首先,导入这些:
import { Provider } from '.../provider';
import createTestStore from '.../test-store';
其次,如果之前没有这样做,请将组件渲染包装在 <Provider> 中。
示例:
<Provider store={createTestStore()}>
<Component {...props} />
</Provider>
确保满足所有 10 个条件。转换后的文件应该可以在不进行任何手动更改的情况下由 Jest 运行。
其他指令部分,适用时使用:
1. "data-qa" 属性配置为与 "screen.getByTestId" 查询一起使用。
2. 使用这些 4 个增强的匹配器,它们以 "DOM" 结尾,以避免与 Enzyme 冲突
toBeCheckedDOM: toBeChecked,
toBeDisabledDOM: toBeDisabled,
toHaveStyleDOM: toHaveStyle,
toHaveValueDOM: toHaveValue
3. 对于用户模拟,请使用 userEvent 并使用 "import userEvent from '@testing-library/user-event';" 导入它
4. 按以下顺序优先查询 getByRole, getByPlaceholderText, getByText, getByDisplayValue, getByAltText, getByTitle, 然后是 getByTestId。
5. 仅在非存在检查中使用 query* 变体:示例 "expect(screen.query*('example')).not.toBeInTheDocument();"
6. 确保所有文本/字符串都转换为小写正则表达式。示例:screen.getByText(/your text here/i), screen.getByRole('button', {name: /your text here/i}).
7. 当断言 DOM 没有渲染任何内容时,用 toBeEmptyDOMElement() 替换 isEmptyRender()).toBe(true),通过将组件包装到容器中。示例:expect(container).toBeEmptyDOMElement();`
评估和呈现结果的指示:
`现在,请评估您的输出,并确保您的转换代码在 <code></code> 标签之间。
如果有任何偏离指定条件的情况,请明确列出。
如果输出符合所有条件并使用指令部分,您可以简单地声明 "输出符合所有指定条件。"`
我们用来控制 LLM 输出的第二种可能更有效的方法就是使用 AST 转换。这种方法在行业中很少见。我们没有完全依赖提示工程,而是将我们初始基于 AST 的 codemod 生成的部分转换代码和建议整合到我们的请求中。将 AST 转换的代码包含在我们的请求中取得了显著的成果。通过自动化转换更简单的案例,并在转换文件的注释中为所有其他实例提供注释,我们成功地最小化了 LLM 的幻觉和无意义的转换。这种技术在我们的转换过程中发挥了关键作用。现在,我们已经建立了一个强大的框架,用于管理复杂和动态的代码转换,利用多种信息源,包括提示、DOM、测试文件代码、React 代码、测试运行日志、linter 日志和 AST 转换的代码。值得注意的是,只有 LLM 能够整合这种不同类型的信息;我们没有的其他工具具备这种能力。
评估和影响
评估和影响评估是我们项目的关键组成部分,允许我们衡量我们方法的有效性,量化 AI 驱动解决方案的好处,并验证通过 AI 集成实现的时间节省。
我们通过按需运行简化了转换过程,仅在 2-5 分钟内提供结果,以及通过 CI 夜间作业处理数百个文件,而不会压垮我们的基础设施。每个夜间运行中转换的文件根据其转换状态进行分类 - 完全转换,部分转换有 50-99% 的测试用例通过,部分转换有 20-49% 的测试用例通过,或部分转换有不到 20% 的测试用例通过 - 这使开发人员能够轻松识别和使用最有效的转换文件。这种设置不仅通过让开发人员免于运行脚本来节省时间,而且还使他们能够本地调整和完善原始文件,以提高 LLM 的性能,使用本地按需运行。
值得注意的是,我们的采用率,计算为我们的 codemod 运行的文件数量除以转换为 RTL 的总文件数量,达到了大约 64%。这个采用率突出了我们的 codemod 工具由前端开发人员作为主要消费者显著利用,从而节省了大量时间。
我们从两个关键维度评估了我们的 AI 驱动的 codemod 的有效性:在特定测试文件上手动评估代码质量,以及在更大的测试文件集上测试用例的通过率。对于手动评估,我们分析了九个不同复杂性(三个简单,三个中等,三个复杂)的测试文件,这些文件由 LLM 和前端开发人员转换。我们的质量基准是由前端开发人员根据我们的质量准则实现的标准,涵盖导入、渲染方法、JavaScript/TypeScript 逻辑和 Jest 断言。我们的目标是达到他们的质量水平。评估显示,这些文件中 80% 的内容被准确转换,其余 20% 需要手动干预。
我们分析的第二个维度深入探讨了文件集的测试用例通过率。我们检查了大约 2,300 个单独的测试用例的转换率,这些测试用例分布在 338 个文件中。其中,大约 500 个测试用例成功转换、执行并通过。这突出了 AI 的有效性,导致开发人员时间节省了 22%。值得注意的是,这 22% 的时间节省只代表了记录在案的通过测试用例的案例。然而,可以想象,一些测试用例可能已经正确转换,但由于设置或导入语法等问题,测试文件可能根本无法运行,这些情况下的时间节省没有被计算在内。这种以数据为中心的方法提供了明确的时间节省证据,最终证实了 AI 驱动解决方案的强大影响。值得注意的是,生成的代码在合并到我们的主要存储库之前由人类手动验证,确保了自动化转换过程的质量和准确性,同时保持了人类专业知识的参与。
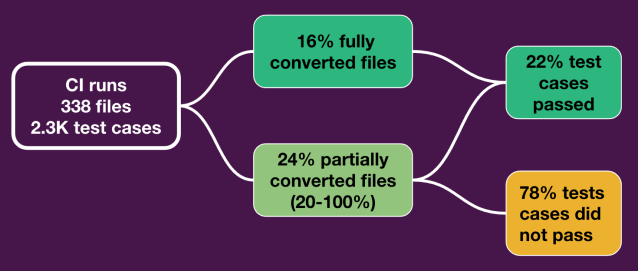
带有转换结果的图表
随着我们的项目在 2024 年 5 月接近尾声,我们仍在收集数据和评估我们的进展。到目前为止,显然 LLM 为开发人员体验提供了有价值的支持,对他们的生产力产生了积极影响,为我们的工具库增加了另一种工具。然而,围绕代码生成的信息稀缺,特别是 Enzyme 到 RTL 转换,表明这是一个高度复杂的问题,AI 可能无法成为这种转换的终极工具。虽然我们的经验在某种程度上是幸运的,因为我们使用的模型具有 JavaScript 和 TypeScript 的开箱即用能力,我们没有进行任何额外的训练,但很明显,要充分利用任何 LLM 潜力,可能需要定制实现。
我们的定制 Enzyme 到 RTL 转换工具到目前为止证明是有效的。它为大规模迁移展示了可靠的性能,为前端开发人员节省了明显的时间,并收到了我们用户的积极反馈。这个成功证实了我们对这种自动化的投资价值。展望未来,我们渴望探索自动化前端单元测试生成,这是一个在我们开发人员中引起兴奋和乐观的话题,关于 AI 的潜力。
此外,作为前端测试框架团队的成员,我要感谢我们团队成员的合作、支持和奉献。我们一起创建了这个转换管道,进行了严格的测试,迅速改进,并对 AST codemod 做出了杰出的贡献,显著提高了我们 AI 驱动项目的质量和效率。此外,我们感谢 Slack DevXP AI 团队在利用我们的 LLM 方面提供了卓越的体验,并耐心地回答了所有询问。他们的支持对我们简化工作流程和实现开发目标至关重要。这些团队共同体现了协作和创新,体现了我们 Slack 工程社区内的卓越精神。