本周我参加了斯坦福举办的Story Discovery At Scale数据新闻会议。在任何新闻会议上,数据提取都是一个长久热门的话题:我们如何最好地从PDF和图像中提取数据?
最近我用Gemini Pro 1.5、Claude 3和GPT-4 Vision取得了一些非常有希望的结果,不久我会写更多相关内容。但这些工具对大多数人来说仍然不方便使用。
与此同时,像Tesseract OCR这样的老工具仍然非常有用——只要它们更容易使用就好了。
然后我想起了,如今由于优秀的Tesseract.js项目,Tesseract可以愉快地在浏览器中运行。而且,由于Mozilla极其成熟且经过充分测试的PDF.js库,也可以使用JavaScript处理PDF。
所以我构建了一个新工具!
tools.simonwillison.net/ocr 提供了一个单页Web应用程序,可以对在应用程序中打开的(或拖放到其中的)图像或PDF运行Tesseract OCR。
至关重要的是,一切都在浏览器中运行。这里没有服务器组件,也没有上传任何东西。您的图像和文档永远不会离开您的计算机或手机。
这是一个动画演示:
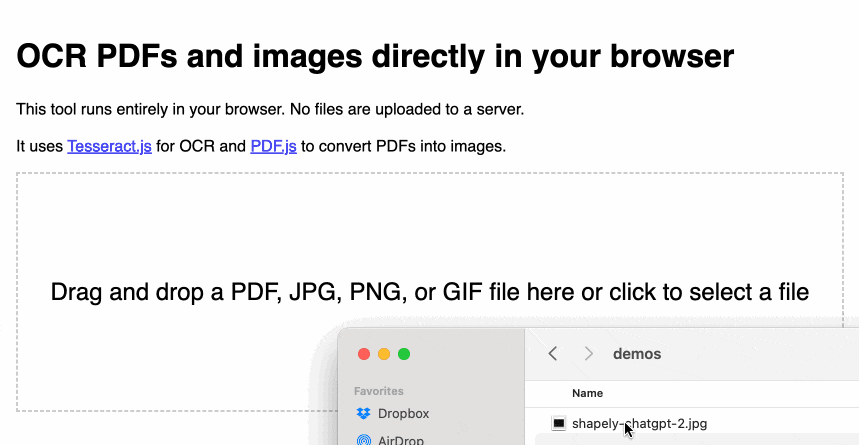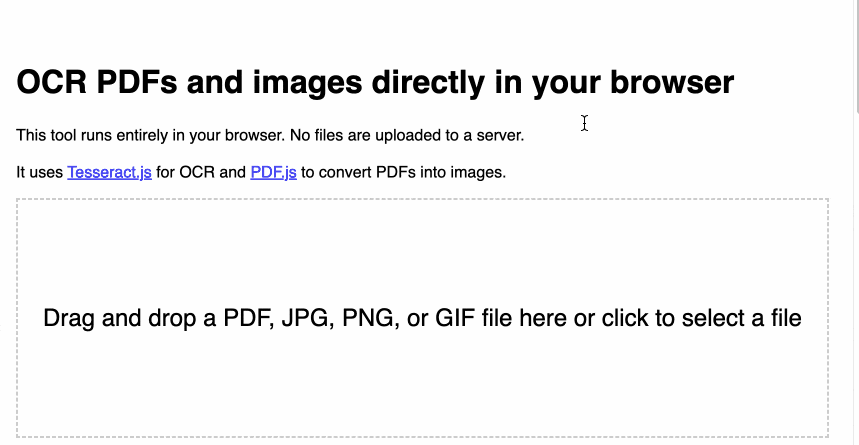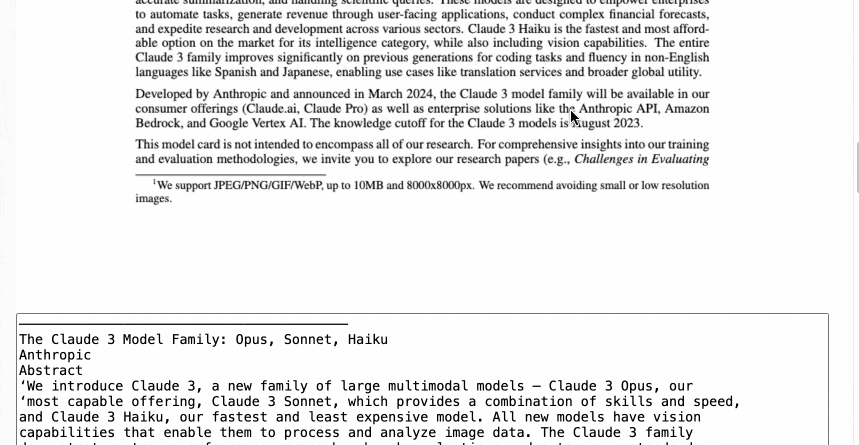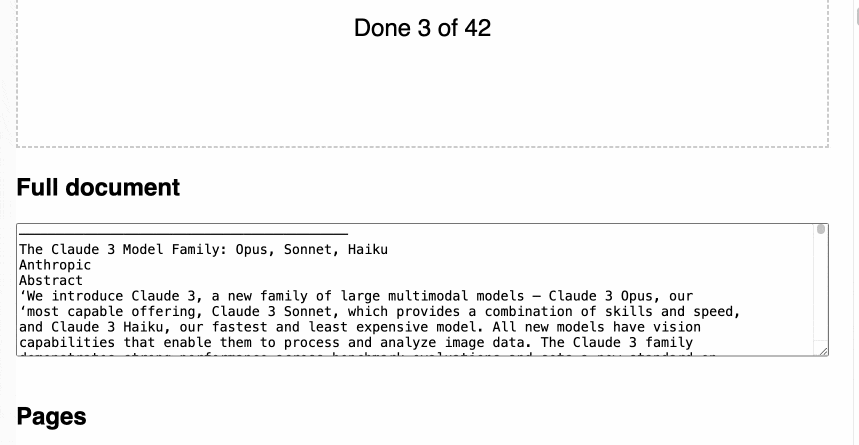
它并不完美:多列PDF(感谢学术界)将被视为单列,插图或照片可能导致ASCII艺术被搞乱,还有许多其他会使它出错的边缘情况。
但是…在Web浏览器中使用Tesseract OCR对PDF进行处理(包括在Mobile Safari中)仍然是一件非常有用的事情。
我如何构建这个工具#
有关我借助LLM构建项目的更多最新示例,请参阅使用ChatGPT代码解释器为SQLite构建和测试C扩展和为临时任务使用Claude和ChatGPT。
我只用了几分钟就构建了这个工具的第一个版本,使用了Claude 3 Opus。
我已经有了我自己的JavaScript代码,用于两个最重要的任务:对图像运行Tesseract.js和使用PDF.js将PDF转换为一系列图像。
OCR代码来自我建立的系统,可以在How I make annotated presentations中找到解释(借助多次ChatGPT会话的帮助)。PDF转图像的代码来自一个未完成的实验,我一个星期前用Claude 3 Opus的帮助写了出来。
我为Claude 3编写了以下提示,我将我的两个代码示例粘贴到其中,然后在末尾添加了一些关于我想让它构建的内容的说明:
此代码显示如何打开PDF并将其转换为每页一个图像:
<!DOCTYPE html>
<html>
<head>
<title>PDF to Images</title>
<script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.9.359/pdf.min.js"></script>
<style>
.image-container img {
margin-bottom: 10px;
}
.image-container p {
margin: 0;
font-size: 14px;
color: #888;
}
</style>
</head>
<body>
<input type="file" id="fileInput" accept=".pdf" />
<div class="image-container"></div>
<script>
const desiredWidth = 800;
const fileInput = document.getElementById('fileInput');
const imageContainer = document.querySelector('.image-container');
fileInput.addEventListener('change', handleFileUpload);
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.9.359/pdf.worker.min.js';
async function handleFileUpload(event) {
const file = event.target.files[0];
const imageIterator = convertPDFToImages(file);
for await (const { imageURL, size } of imageIterator) {
const imgElement = document.createElement('img');
imgElement.src = imageURL;
imageContainer.appendChild(imgElement);
const sizeElement = document.createElement('p');
sizeElement.textContent = `Size: ${formatSize(size)}`;
imageContainer.appendChild(sizeElement);
}
}
async function* convertPDFToImages(file) {
try {
const pdf = await pdfjsLib.getDocument(URL.createObjectURL(file)).promise;
const numPages = pdf.numPages;
for (let i = 1; i <= numPages; i++) {
const page = await pdf.getPage(i);
const viewport = page.getViewport({ scale: 1 });
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
canvas.width = desiredWidth;
canvas.height = (desiredWidth / viewport.width) * viewport.height;
const renderContext = {
canvasContext: context,
viewport: page.getViewport({ scale: desiredWidth / viewport.width }),
};
await page.render(renderContext).promise;
const imageURL = canvas.toDataURL('image/jpeg', 0.8);
const size = calculateSize(imageURL);
yield { imageURL, size };
}
} catch (error) {
console.error('Error:', error);
}
}
function calculateSize(imageURL) {
const base64Length = imageURL.length - 'data:image/jpeg;base64,'.length;
const sizeInBytes = Math.ceil(base64Length * 0.75);
return sizeInBytes;
}
function formatSize(size) {
const sizeInKB = (size / 1024).toFixed(2);
return `${sizeInKB} KB`;
}
</script>
</body>
</html>
此代码显示如何对图像进行OCR:
async function ocrMissingAltText() {
// Load Tesseract
var s = document.createElement("script");
s.src = "https://unpkg.com/tesseract.js@v2.1.0/dist/tesseract.min.js";
document.head.appendChild(s);
s.onload = async () => {
const images = document.getElementsByTagName("img");
const worker = Tesseract.createWorker();
await worker.load();
await worker.loadLanguage("eng");
await worker.initialize("eng");
ocrButton.innerText = "Running OCR...";
// Iterate through all the images in the output div
for (const img of images) {
const altTextarea = img.parentNode.querySelector(".textarea-alt");
// Check if the alt textarea is empty
if (altTextarea.value === "") {
const imageUrl = img.src;
var {
data: { text },
} = await worker.recognize(imageUrl);
altTextarea.value = text; // Set the OCR result to the alt textarea
progressBar.value += 1;
}
}
await worker.terminate();
ocrButton.innerText = "OCR complete";
};
}
使用这些示例将一个单独的HTML页面与嵌入的HTML、CSS和JavaScript放在一起,提供一个大方块,用户可以拖放PDF文件到其中,当他们这样做时,PDF的每一页都会转换为JPEG并显示在页面下方,然后运行Tesseract OCR,结果显示在每个图像下方的文本区块中。
我将这个提示保存为prompt.txt文件,并使用我的llm-claude-3插件运行它,LLM:
llm -m claude-3-opus < prompt.txt
它在第一次尝试时给了我一个可工作的初始版本!

这是完整的记录,包括我的后续提示及其响应。通过这种方式迭代软件是非常有趣的。
首次跟进:
修改此内容,使其还可以使用文件输入,将文件拖放到拖放区域会填充该输入
使拖放区域宽度为100%,但在body上设置2em的填充。高度应为10em。当拖放图像时,它应变为粉色。
每个文本区域应为100%宽,10em高
在页面底部添加一个标题为Full document的h2,然后是一个30em高的文本区域,其中包含每页的文本,用两个新行分隔
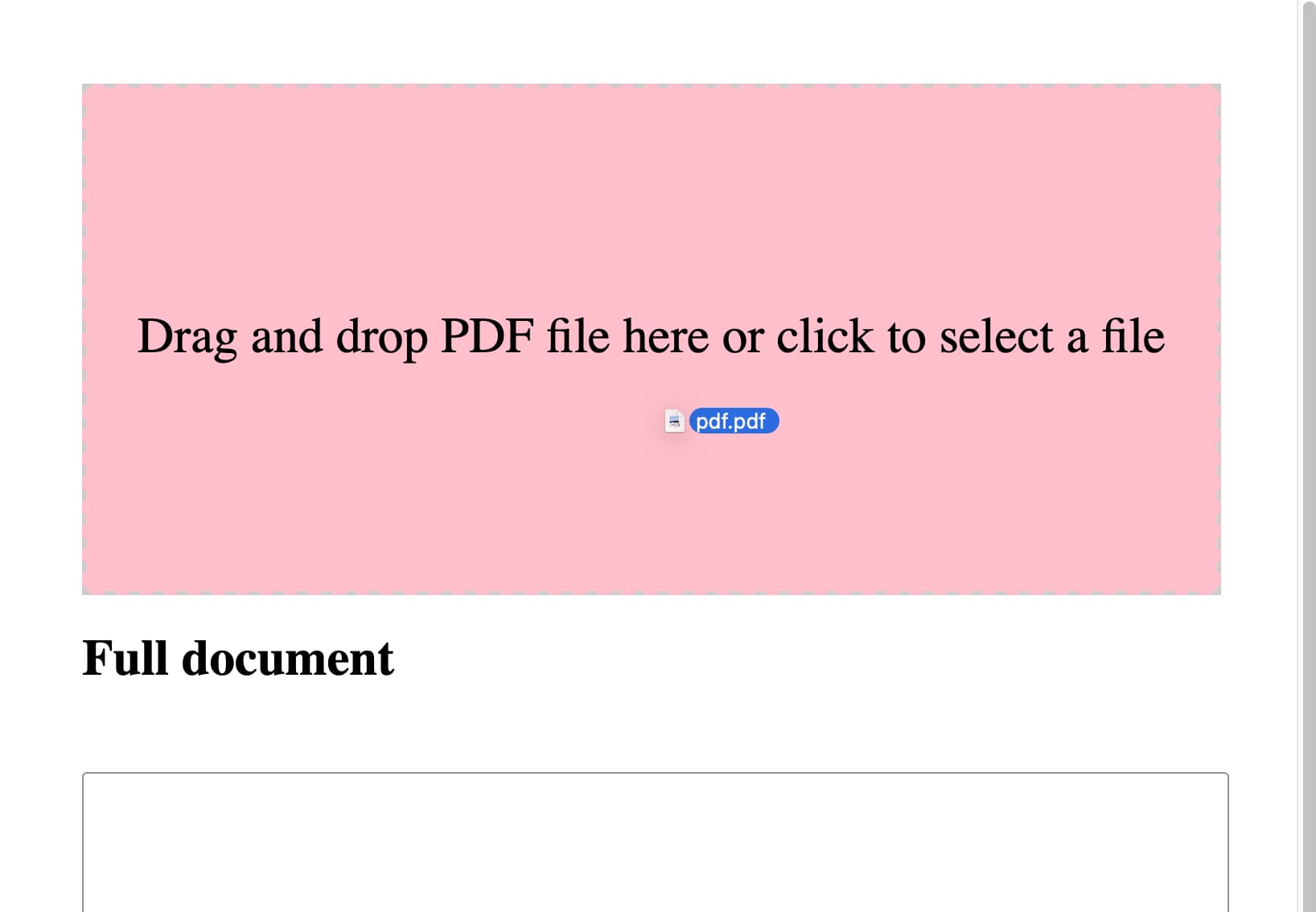
令人愉快的是,它使用了更整洁的模式,其中文件输入本身是隐藏的,但可以通过点击大的拖放区域来触发,它还更新了拖放区域上的文本,以反映这些要求——而我没有建议这些要求。
然后:
删除显示图像大小的代码。在每个文本区域上设置占位符为Processing…,在任务完成时清除该占位符。
我意识到如果它还能处理非PDF图像会很有用。因此,我启动了ChatGPT(没有别的原因,只是好奇看看它的表现如何),让GPT-4为我添加了该功能。我粘贴了迄今为止的代码,并添加了:
修改此代码,以便也可以拖放或打开jpg和png和gif图像 - 它们跳过PDF步骤并直接附加到页面并进行OCR。还将完整的文档标题和文本区域移至页面预览上方,并隐藏它,直到其中有数据显示为止
然后我注意到Tesseract worker在循环中被创建了多次,这是低效的——所以我提示:
创建一个worker,一次用于所有OCR任务,并在结束时终止它
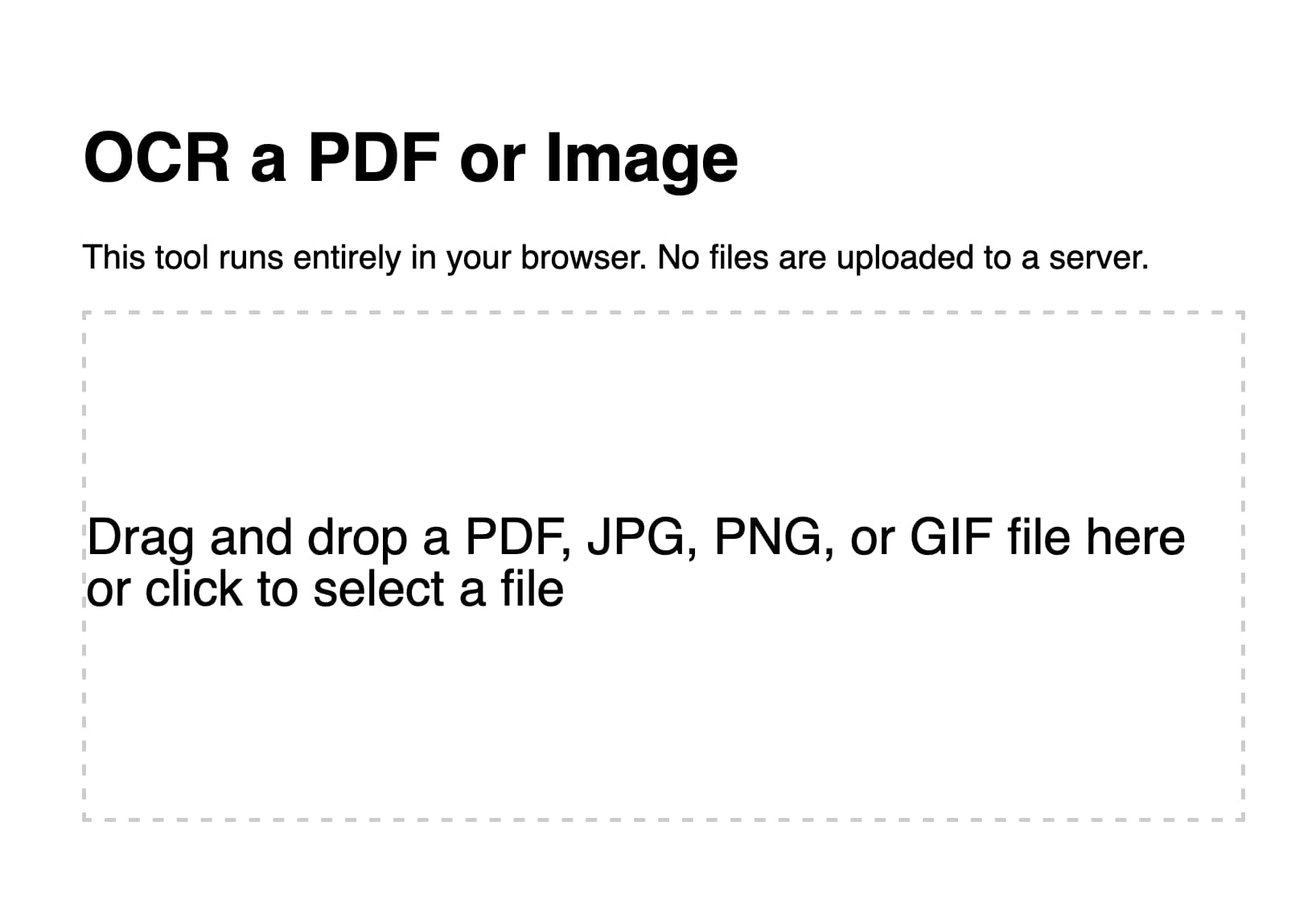
在将HTML和CSS输入到GPT-4之前,我对其进行了微调,所以现在网站有了标题并且使用Helvetica呈现。
这是GPT-4为我生成的版本。
手动的最后一点润色#
尽管完全通过提示对这个项目进行迭代很有趣,但我决定自己进行最后的润色会更有成效。您可以在提交历史记录中看到这些润色。它们并不是特别有趣:
- 我添加了Plausible分析(我喜欢它因为它不使用cookie)。
- 我添加了更好的进度指示器,包括显示到目前为止已处理了PDF的多少页的文本。
- 我将渲染的PDF页面图像的宽度从800增加到1000。这似乎提高了OCR的质量,特别是Claude 3模型卡PDF现在比以前错误更少。
- 我将Tesseract.js和PDF.js升级到最新版本。毫不奇怪,Claude 3 Opus使用了这两个库的旧版本。
我对这个项目非常满意。我认为它已经完成了任务,并且我没有看到继续对其进行迭代的必要性。因为它是全部静态的JavaScript和WebAssembly,我预计它会一直有效地运行下去。
更新:好吧,还有一些功能:我添加了语言选择、粘贴支持以及使用Playwright Python进行了一些基本的自动化测试。