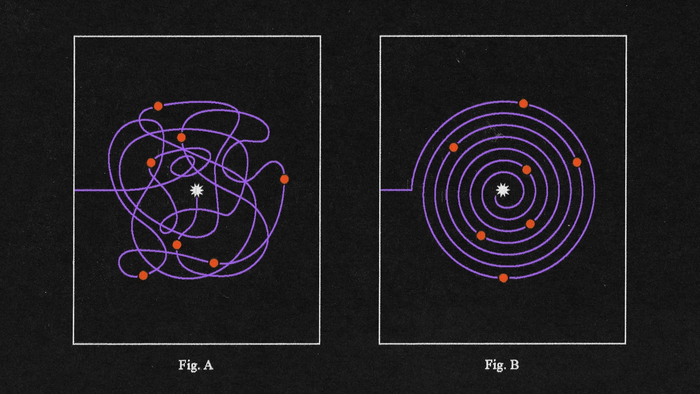
当我们的权限系统出现问题时,一切都陷入了停顿。这是我们如何修复它的故事,同时提高性能、准确性和开发人员的舒适度。
协作是Figma的核心。这是我们将Figma构建在网络上的原因,也是Figma编辑器中的多人游戏为何如此重要的原因。这种对协作的关注也意味着我们的权限规则非常复杂,甚至是具有欺骗性的。在2021年初,工程团队遇到了许多与这种复杂性有关的错误、支持工单和延迟的项目。挑战是什么?我们必须重新思考我们权限引擎的技术基础,以确保工程师可以添加、修改和删除规则,而不必担心破坏某些东西。
在“构建”与“购买”的辩论中,我们倾向于使用现有的开源或现成的解决方案。在这种情况下,我们选择创建自己的权限领域特定语言(DSL),一个自定义的跨平台逻辑引擎,并将我们所有最重要的权限规则迁移到这个系统中。
Figma上的权限和授权
在讨论我们为什么要采取这种解决方案之前,了解这与Figma用户体验的联系是很重要的。让我们从我们称之为“分享”模态框开始。这当然不是唯一使用权限的地方,但它是最可见和最复杂的之一。
当您点击Figma文件中的“分享”按钮时,分享模态框弹出,控制着谁能访问文件以及他们相应的创作权限。访问文件有两种主要方式:通过角色和通过链接。角色是分层的,因此您可能通过父文件夹、团队或组织中的角色来访问文件。我们对于这些容器的状态和用户角色有相应的规则,决定是否阻止或允许访问。链接访问也可能有不同的规则,限制谁能访问文件、他们有何种类型的访问权限、持续多久、是否需要密码,甚至文件的父组织是否对如何共享该文件施加限制等。
在早期,Figma的所有后端业务逻辑,包括权限,都驻留在一个使用ActiveRecord的Ruby单体应用程序中,ActiveRecord是Ruby最流行的对象关系映射器(ORM)。几乎所有的业务逻辑都由简单的HTTP端点和ActiveRecord调用组成。ActiveRecord模型有一个 has_access? 方法,它定义了用户(仅一个!)对特定资源具有访问权限的逻辑。这个方法作为后端应用程序中访问控制的基础,不过不过是一个包含“if/else”语句的函数,该函数进行数据库调用并返回布尔值。此函数处理删除的文件、分层访问、所有不同类型的链接访问、组织限制、计费规则以及许多其他方面。为了确保用户对特定资源有访问权限,产品工程师随后需要在控制器中适时调用此函数。虽然这种简单的设置长期以来运作良好,但很明显我们已经超出了它的能力范围。
随着时间的推移,工程师们开始抱怨处理权限的难度。这引发了一次深入调查,让我们就要解决的四个关键问题达成一致。
问题1:不必要的复杂性和调试困难
这些 has_access? 方法非常长且复杂,具有许多可选参数。工程师们不敢修改它们。您经常会听到像“我们可以在 has_access? 之外做吗?”或“我们为什么不在客户端做这个?”这样的建议。但是这些函数中的错误可能会泄漏对Figma中的每个文件的访问权限。
这种复杂性的一个有趣原因是,当调试这些函数时,工程师们同时也在调试该资源的所有权限逻辑。没有一种简单的方法来解耦这种逻辑。因此,工程师们很难在不考虑所有现有逻辑的情况下为自己的特性编写新的独立规则。
调试变得复杂且耗时,通常包括在这些函数中随处添加数十个打印语句,并且需要为整个权限逻辑提供大量的上下文。
问题2:分层权限
我们发现,即使我们有一个基于权限的整数值的分层系统,工程师们经常通过向 has_access? 方法添加的布尔标志引入这些行为的变化。这些方法通常
看起来像这样:
def has_access?(
user, # T.nilable(User)
level, # Integer
ignore_link_access: false, # Boolean
org_candidate: false, # Boolean
ignore_archived_branch: false # Boolean
)
这意味着用户可能具有 300级访问权限(编辑权限),但可能没有 100级(查看)+ ignore_link_access: true 的访问权限。这使得非常难以理解和调试。此外,这些标志会因资源而异。工程师们必须了解所有这些变化,它们的含义以及何时考虑它们。
很明显,我们需要一个更灵活的系统,允许创建非分层、细粒度的权限,这些权限可以完全独立于彼此。虽然分层权限有一定用处,但我们仍然希望超出已建立的层次结构或创建新的层次结构。
问题3:数据库负载
Figma正在快速增长。随之而来的是对我们数据库的越来越大的压力,权限检查所占的数据库负载占比很大(约20%)。这是一个存在问题,因为我们的数据库可以承受的大小有着物理限制。尽管数据库团队正在进行垂直和水平划分的工作,但我们需要确保能够为后端工程师提供对权限数据层的更多控制。
Figma工程师Tim Liang写了关于数据库架构的成长之痛。阅读他的反思。
当我们开始研究这个问题时,我们意识到,因为 has_access? 只是一个普通的Ruby函数,其中包含了ActiveRecord调用,数据库查询和权限逻辑被耦合在一起。修复数据库查询而不会意外更改权限逻辑是不可能的。如果您是一个没有权限知识的后端工程师,尝试更改任何内容会感觉很危险。我们希望有一种完全分离数据库查询和策略逻辑的方法。
问题4:真实性的多个来源
我们需要在两个系统上实施权限:Sinatra(我们的HTTP后端)和LiveGraph,我们的实时API层。每当引入新的权限逻辑时,工程师们被指示在这两个代码库中进行更改。实际上,许多规则没有得到正确迁移,结果在这两个系统之间的差异导致了错误。我们需要一种方法,使工程师可以编写一次他们的策略逻辑,并且在这两个系统中都能正常工作。
根据这四个问题,我们意识到无论我们的解决方案是什么,它都需要:
- 允许工程师编写权限规则,而不必关心现有的权限规则。解耦这些规则将使它们易于调试和修改。
- 在策略逻辑和数据加载之间完全分离。策略作者不应该担心他们的数据如何加载或优化他们的策略;在权限引擎上工作的后端工程师不应该担心策略逻辑。
- 是跨平台的。它需要能够在Ruby、TypeScript和任何其他语言中工作,而不会给策略作者带来额外的工作。
- 允许创建细粒度的权限,以更精确地对用户对资源的操作进行建模。
策略:初始见解和概念验证
很明显,我们需要某种抽象层来声明权限规则。作为定义权限角色的声明性方式的灵感,我们开始研究AWS IAM策略。IAM策略基本上具有几个主要属性:一组权限或操作,一个效果(允许或拒绝),它适用于的资源,以及可能适用该策略的一些条件。它们通常以JSON格式编写,看起来像这样:
{
"Version": "2012–10–17",
"Statement": {
"Effect": "Allow",
"Action": "EC2:*",
"Resource": "*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [ "192.168.0.1" ] }
}
}
}
现在,让我们明确一下:AWS IAM策略以难以处理而著称,肯定不是普遍受到喜爱的。但对于我们来说,它们提供了细粒度和隔离性,这是我们系统的关键部分:策略作者可以编写IAM策略,而不必担心所有其他现有的IAM策略。诸如效果(允许或拒绝)、权限集(操作或动词)以及根据应用策略的条件集等附加属性似乎都与我们希望采用的方向相匹配。以此为灵
感,我们开始寻找可能解决此问题的潜在解决方案,但似乎没有任何东西能够满足我们的需求。开放策略代理、Zanzibar和Oso是我们考虑的一些解决方案,但都没有真正解决我们试图解决的核心问题。经过深入调查,我们开始探索我们自己的解决方案。
在我们的首次尝试中,我们开发了一个策略类,最终看起来像这样:
class DeletedFileACP < AccessControlPolicy
# 此策略适用于哪种类型的资源
resource_type :file
# 如果应用,指定的权限应该是允许还是拒绝(拒绝会覆盖允许)。
effect :deny
# 当应用或拒绝此策略时,应该允许/拒绝的操作。
permissions [ :can_edit, :can_view ]
# 我们需要加载哪些数据以评估此策略。在这种情况下,资源将是文件对象。
# (我们最终放弃了这个想法!)
attached_through :resource
# 如果应用,是否应用此策略或忽略。
# 如果应用,则权限将被允许/拒绝。
def apply?(resource: nil, **_)
resource.deleted?
end
end
它包含了一个效果、一组权限、一个资源类型和一个 apply? 方法,该方法仅在给定一组已加载的资源时执行Ruby代码。此外,attached_through 允许附加资源,例如用户、角色、父资源(项目、团队、组织)或类似资源。这个概念最后证明是不直观且限制性的(您只能加载一个资源?),我们觉得应该对其进行迭代。
有一个问题一直萦绕在我们心头:我们是否能够使用这种策略模型来表示Figma的许多现有的权限规则?只有一种方法可以找出来!我们开始将所有逻辑分成策略。确保我们在这些函数中定义了所有逻辑,并且所有现有的测试都通过了,这证明是一项艰巨的任务。经过数周的仔细来回与CI的交互和大量的迭代之后,我们最终得到了我们需要的东西:一个分支,其中所有权限都用策略表达,并且所有测试在CI/CD中都通过了。这些测试已经写了很多年,所以我们对我们所拥有的内容相当有信心。
在许多方面,这最终成为了项目风险最小化的最大一步。通过这项工作,我们能够了解工程师多年来添加的所有权限规则的小细节以及其背后的产品原因。
此时,我们在一种语言中有了一个可行的概念验证和一个绿色的分支,但我们仍然有一些问题要解决:
- 策略仍然很难编写。 “附加”资源并具有这些复杂关系的整个概念似乎比仅指定策略所需的资源更难。
- 我们编写的命令式Ruby函数意味着我们对
apply?方法中实际发生的事情几乎没有控制。我们希望策略只执行布尔逻辑,而不执行任何网络调用(例如,加载数据)或副作用。 - 我们仍然没有一个良好的故事,关于我们如何使这些策略在各个平台上工作。我们开始尝试使用抽象语法树(AST),并将其解释为Java、Ruby和TypeScript,但这不太理想。
引入DSL:改进开发人员的人性化和内省
在开发了这个最初的概念验证后,我们想要解决跨平台支持的问题。为了做到这一点,我们决定使所有策略都可JSON序列化,因此在Sinatra和LiveGraph中都易于阅读。此外,策略将是完全抽象的,不包含任何代码执行。无需AST解析。
我们首先扩展了一个名为 ExpressionDef(或“表达式定义”)的现有DSL,该DSL由LiveGraph团队使用。这个布尔逻辑DSL基于包含两个变量和一个操作的三元组,两边分别是变量,中间是操作,这将计算为布尔值([1,“=”,1]等于true,[2,“>”,3]等于false)。有了这些三元组作为基础,您就可以使用三个更高级的操作构建更复杂的布尔逻辑:and、or和not。有了这些,您就可以表达诸如以下内容的内容:{ “and”: [[1,“=”,1],[1701439764,“>”,1701439775]] }或{ “or”: [[1,“=”,1],[1701439764,“>”,1701439775]] }(分别计算为true和false)。
这个可JSON序列化的DSL的第二部分是能够引用提供给它的数据。为此,我们进行了两个小的修改:首先,三元组的左侧始终是对数据字段的引用,其次,您总是可以通过使用特殊的 ref 对象来引用右侧的数据字段。数据字段将通过字符串表示,其中表名和列名用 “.” 分隔。您可以编写如下语句:
["team.permission", "=", "open"]["file.deleted_at", "<>", null]["file.team_id", "=", { "ref": "user.blocked_team_id" }]
您可能会注意到,我们在这里使用通用术语,如 “team”、“file” 和 “user”,来引用字段。这实际上是我们在策略中使用的确切命名规范。引擎负责处理这些字符串,但我们喜欢这种模型的简洁性。
Expression Definitions为我们打开了许多大门,因为现在我们可以:
- 在任何我们想要的语言或环境中轻松消耗策略及其逻辑,无需AST解析。
- 通过非常简单的解析,静态地知道我们所需的所有数据依赖关系。
- 为策略作者提供一个简单、直观的API,在其中他们可以直接引用所有需要的数据。
我们选择使用TypeScript作为编写这些策略的语言,因为它在Figma中已经被广泛使用,具有类型系统,并且很容易将对象序列化为JSON。此外,我们所基于的原始 ExpressionDefs 也是用TypeScript编写的,这将使它更容易与LiveGraph和其他现有系统集成。使用TypeScript,我们添加了类型和变量,以使编写这些策略更容易。我们为所有可用字段添加了类型,为一些最常见的操作添加了便利函数。最后,策略最终看起来像这样:
class DenyEditsForRestrictedTeamUser extends DenyFilePermissionsPolicy {
description = 'This user has a viewer-restricted seat in a Pro plan, so will not be able to edit the file.'
applyFilter: ExpressionDef = {
and: [
not(isOrgFile(File)),
teamUserHasPaidStatusOnFile(File, TeamUser, '=', AccountType.RESTRICTED),
],
}
// This compiles down to
applyFilter: ExpressionDef = {
and: [
not([file.orgId, '<>', null]),
or([
and(["file.editor_type", "=", "design"], ["team_user.design_paid_status", "=", "restricted"]),
and(["file.editor_type", "=", "figjam"], ["team_user.figjam_paid_status", "=", "restricted"]),
])
],
}
permissions = [FilePermission.CAN_EDIT_CANVAS]
}
您会注意到,大多数值都是使用 enums 或 const 对象强类型化的。没有拼写错误!此外,常用的逻辑片段被写为返回 ExpressionDefs 的函数,这使得许多不同策略之间的易组合性变得容易。这也有助于保持策略之间的一致性。最后,诸如 and、not、or 和 exists 等便利函数为编写这些策略的体验增添了语法糖。
后端实现
为了使这个策略DSL工作,我们需要从逻辑定义转换为实际实现。有两件事是首要考虑的。首先,我们需要一个布尔逻辑评估引擎。这是一个小型库,可以接受表示所需数据的字典的字典和JSON策略声明,并返回策略是否为 true 或 false。我们将其称为 ApplyEvaluator。第二个组件是数据库加载器。我们需要一种方法来从类似 “file.id” 和 “team.created_at” 的字符串转换为加载适当数据以馈送给逻辑引擎的方式。我们将这个组件创造性地称为 DatabaseLoader。
ApplyEvaluator:布尔逻辑引擎
我们的布尔逻辑DSL可以在TypeScript中表示为以下形式:
FieldName,它是一个字符串,表示以“.”分隔的表名和列名(例如“file.name”、“user.email”)。Value,表示基本数据类型。
export type FieldName = string;
export type Value = string | boolean | number | Date | null;
基于这些,我们有一个 BinaryExpressionDef,它是一个三元组,左侧是一个 FieldName,中间是表示所需操作的字符串,右侧是一个 Value 或一个字段引用(ExpressionArgumentRef)。ExpressionArgumentRef 只是包装在对象中的 FieldNames,以区分字符串文字和对 FieldNames 的引用。
export type BinaryExpressionDef = [ FieldName,
'='| '<>' | '>' | '<' | '>=' | '<=',
Value | ExpressionArgumentRef,
]
const type ExpressionArgumentRef = { type: 'field'; ref: FieldName }
最后,这些 BinaryExpressionDef 可以使用 and 和 or 操作符组合。ExpressionDef 是这三种类型的联合。
export type ExpressionDef = | BinaryExpressionDef
| OrExpressionDef
| AndExpressionDef
export type OrExpressionDef = { or: ExpressionDef[]
}
export type AndExpressionDef = { and: ExpressionDef[]
}
现在我们有了一个 ExpressionDef,然后我们可以编写一个简单的函数来评估其中的逻辑,它看起来可能是这样的:
interface Dictionary<T> { [Key: string]: T; }
function evalExpressionDef(expr: ExpressionDef, data: Dictionary<Dictionary<Value>>) {
// 递归遍历ExpressionDefs
if (expr.and) { return expr.and.every(subExpr => evalExpressionDef(subExpr, data) }
if (expr.or) { return expr.or.some(subExpr => evalExpressionDef(subExpr, data) }
// 评估BinaryExpressionDef
const [leftKey, operation, rightKeyOrValue] = expr; // 使用提供的键查找数据中的值
const leftValue : Value = getValueFromKey(leftKey, data); const rightValue : Value = getValueFromKey(rightKeyOrValue, data); // 评估表达式
switch operation { case '='
return leftValue === rightValue // ... }
}
您可以想象,鉴于 ExpressionDefs 可以JSON序列化,我们可以很容易地在任何其他语言中编写一个这样的函数,我们对TypeScript、Ruby和最终Go都是这样做的。虽然维护多种语言中这些引擎的多个实现可能看起来很可怕,但 ExpressionDefs 的简单性使我们能够相当快地(对于资深工程师而言,大约两到三天)在多种语言中编写这些小型库。此外,我们还可以在所有实现中使用完全相同的测试套件,以确保一致性。
数据加载
ExpressionDefs 的主要优点之一是,对于任何权限名称,我们都可以计算出它所需的所有数据依赖关系。我们可以迭代所有具有某个权限的策略,递归地遍历其 ExpressionDef,并返回所有引用的数据字段的列表。这将输出一个字典,其键是表的名称,值是数组的列,它看起来可能是这样的:
{
"file": ["id", "name", "created_at", "deleted_at"],
"team": ["id", "permission", "created_at"],
"org": ["id", "public_link_permission"],
"user": ["id", "email"],
"team_role": ["id", "level"],
"org_user": ["id", "role"]
}
从上面我们知道要查询的表和列,但实际上我们不知道要查询哪些 行。为了了解如何查询这些行,我们需要回到我们的权限函数的API。
我们的权限函数接受三个参数:一个资源,一个用户和一个权限名称:
file.has_permission?(user, CAN_EDIT)
从资源(在本例中是一个 file)和 user 对象中,我们可以推断出我们需要加载所有所需资源所需的所有查询。我们可以想象有四组资源:
- 在调用时已知的资源(
file和user)。 - 通过主资源对象中的外键加载的资源(通过
file)。 - 通过
user对象中的列加载的资源。 - 通过主资源和
user对象中的列加载的资源。
{
// 在调用 `has_permission?` 时已知的资源
"file": ["id", "name", "created_at", "deleted_at"],
"user": ["id", "email"],
// 通过 `file` 对象加载的资源
"team": ["id", "permission", "created_at"], // file.team_id
"org": ["id", "public_link_permission"], // file.org_id
// 通过 `file` 和 `user` 的组合加载的资源
"team_role": ["id", "level"], // file.team_id + user.id
"org_user": ["id", "role"] // file.org + user.id
}
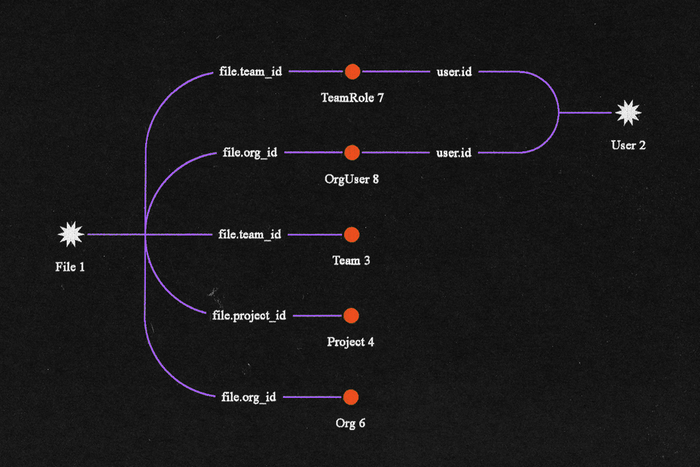
有了这个想法,我们可以使用我们的ActiveRecord模型上的简单函数来定义这些ID,并允许我们查询任何模型:
class File
def context_path {
:project => self.project_id,
:team => self.team_id,
:org => self.org_id,
:file => self.file_id,
}
end
end
class User
def context_path { :user => self.user_id }
end
end
def get_context_path(resource, user)
context_path = {}.merge(resource.context_path).merge(user.context_path)
if context_path[:org] && context_path[:user]
context_path[:org_user] = [context_path[:org],
context_path[:user]]
end
if context_path[:team] && context_path[:user]
context_path[:team_role] = [context_path[:team], context_path[:user]]
end
return context_path
end
现在我们的 context_path 对象包含了加载运行任何给定权限检查所需的所有必要ID。当添加新的可加载资源时,我们需要指定如何填充它们的上下文路径。当添加策略资源时,我们必须确保我们指定其上下文路径。
这个系统的重要优势之一是,一旦我们已经建立了如何查询特定资源的方式,工程师们就不必担心这些关系以及如何查询它们。他们可以轻松地编写只引用 “file”、“user”、“org” 和 “team_role” 的策略,并且不必担心他们正在引用哪些具体行。
这个系统的另一个优势是,我们为后端引擎提供了完全的控制权来决定如何加载数据:以何种顺序加载、使用哪些查询、使用副本还是主数据库、使用数据库的任何接口、使用缓存等等。策略作者不必担心或关心其中的任何一个。
有了所有这些部分,我们可以想象一个基本的算法,看起来像这样:
function hasPermission(resource, user, permissionName) {
// 查找所有相关策略
const policies = ALL_POLICIES .filter(p => p.permissions.include(permissionName)) // 解析策略中所需的所有资源
const resourcesToLoad = policies.reduce((memo, p) => { const dataDependencies = parseDependences(p.applyFilter) return memo.merge(dataDependencies) }, {})
// 加载所有必要的数据
const loadedResources = DatabaseLoader.load(resourceToLoad)
// 将策略二分为DENY和ALLOW策略
const [denyPolicies, allowPolicies] = policies .bisect(p => p.effect === DENY)
// 如果任何DENY策略计算为true,则返回false
const shouldDeny = denyPolicies.any(p => { return ApplyEvaluator.evaluate(loadedResources, p.applyFilter) })
if (shouldDeny) { return false }
// 如果任何ALLOW策略计算为true,则返回true
return allowPolicies.any(p => { return ApplyEvaluator.evaluate(loadedResources, p.applyFilter) })
}
策略定义DSL、ApplyEvaluator 和 DatabaseLoader 成为整个系统的主要构建块。有了这些构建块,我们能够迭代该系统以提高系统的性能。例如,简单的事情,比如不重新评估已经评估为false的策略,以及使用已经在内存中的数据(传递给函数),都有助于提高性能。
DSL:进一步的后果
在初步实现工作并使系统正常运行之后,我们继续迭代,以改善性能、响应用户反馈并使系统更加安全。由此,我们发现了三个非常有趣的特性,这些特性之所以可能,是因为DSL的性质和我们构建的系统。
调试
利用我们的Sinatra数据库加载器和TypeScript的ApplyEvaluator和策略,我们构建了一个前端调试器。Figma的工程师和支持团队可以输入用户ID和资源ID,然后我们会在后端加载所需的所有数据。然后,通过HTTP路由,我们将数据加载到前端,并通过递归组件将我们的ApplyEvaluator集成到React中。因为我们已经有了TypeScript的实现,而且数据加载和逻辑评估相当分离,所以这变得非常简单。此外,它还允许我们完全自由地呈现各种调试信息。用户可以展开和收起and和or权限规则,阅读评估的数据,显示规则是否评估为true或false,通过这种方式找到策略中有问题的地方。
我们还将这个原则扩展到了命令行,用户可以在特定策略上启用调试,在运行测试时传递环境变量,并获取有关策略如何被评估的详细信息。
[DenyEditsForNonPaidOrgUser] Filter passed to should_apply:
[AND] true:
- ["file.parent_org_id"]: 5281 <> null : true
[NOT] true:
[AND] false:
- ["file.parent_org_id"]: 5281 <> null : true
- ["file.team_id"]: 6697 = null : false
- ["file.folder_id"]: 21654 <> null : true
- ["org_user.drafts_folder_id"]: 21652 = { "ref": "file.folder_id"} : false
[OR] true:
[OR] true:
[AND] true:
- ["file.editor_type"]: "design" = "design" : true
- ["org_user.account_type"]: "restricted" = "restricted" : true
再一次,我们这里的DSL为我们提供了构建这种工具所需的所有灵活性,相当容易地实现了这个目标。
性能:惰性加载、短路
在我们的平台初步实现后,我们花了一些时间尝试优化和提高实现的性能。我们知道某些权限可能实际上加载了十几个不同的表。这不是因为所有这些数据都是必需的,而是因为用户可以以多种方式访问资源(多个允许策略)。在我们的系统中,虽然所有拒绝策略 必须 评估为false,但我们只需要一个允许策略评估为true,用户就可以获得权限。
因此,我们希望只加载所需数据的一部分,并使用该信息评估策略。如果我们有了明确的true或false评估,我们可以提前退出,而无需进行任何额外的数据库访问。如果我们无法明确评估策略为true或false,我们将继续从数据库加载数据,直到我们得到明确的答案。为了进行此优化,我们需要从我们的ApplyEvaluator中获得一个新特性:我们需要ApplyEvaluator告诉我们何时一个策略片段无法明确评估。
例如,如果我们看一下以下ExpressionDef,我们可以看到如果我们有以下数据和以下ExpressionDef,我们实际上不需要继续评估策略,因为我们知道从逻辑上讲,这个表达式将始终评估为true。
{ // Data
"team": {
"permission": "secret"
},
"file": PENDING_LOAD, // We have not attempted to load this row!
"project": PENDING_LOAD,
}
{ // ExpressionDef
"and": [ // false
["file.id", "<>", null], // ?
["team.permission", "=", "open"], // false
["project.deleted_at", "<>", null], // ?
]
}
如果给定相同的数据,我们将父语句更改为“or”,我们现在需要知道“file.id”和“project.deleted_at”,以便能够说出该策略实际上是true还是false。
{
"or": [
["file.id", "<>", null],
["team.permission", "=", "open"], // false
["project.deleted_at", "<>", null],
]
}
这实际上是一个第三个不确定状态,与true和false完全不同。我们用null表示了这种不确定状态,意味着我们无法得出结论,无法明确评估策略。
我们使用这种新状态来优化我们的数据库加载。当我们收集我们策略的所有数据要求时,我们将所有表依赖关系分成一组离散的加载步骤,以便按顺序加载。我们主要根据我们知道哪些表最常导致评估权限决策的启发式决定如何划分这个列表。文件、文件夹和团队角色是用户获取资源访问权限的第二种最常见方式(在链接访问之后);我们优先考虑这些加载计划。生成了这个数组之后,我们迭代它以加载所有这些资源并将它们提供给ApplyEvaluator。如果ApplyEvaluator返回true或false,那么意味着我们可以短路执行并返回结果。如果它返回null,那么我们将加载我们需要的下一批资源。这个相当简单的优化将我们的权限评估总执行时间减少了一半以上,并允许我们最小化数据库使用。
静态分析
最后,选择DSL的另一个巨大优势是在我们的策略
上进行静态分析变得非常容易。在开发新功能的不同阶段,我们发现了许多与策略中的逻辑问题相关的错误。我们发现的最明显的问题是BinaryExpressionDefs中心是=操作,右侧是字段引用,其中两个值都评估为null。
{
"file": { "team_id": null }, "team": { "id": null }
}
["file.id", "=", { "ref": "team.id" }]
这个条件实际上会评估为true,但可以说这可能不是策略作者打算表达的意思。
策略作者应该做的是确保这些字段中的一个不是null。这可以很容易地通过在“and”下进行同级检查来完成:
{
"and": {
["team.id", "<>", null],
["file.id", "=", { "ref": "team.id" }] }
}
基于此,我们在单元测试中引入了一个linter,该linter会遍历所有策略ExpressionDefs,如果带有=操作的右侧字段引用没有在“and”ExpressionDefs下有相应的兄弟<> null检查,则会抛出错误。基本上,如果你没有确保这两个引用中的一个不是null,我们就不允许比较两个字段名称。我们还实现了与<>检查相关的类似规则。
由于我们的DSL是JSON可序列化的,编写此linter不涉及任何专门的AST解析或类似操作。相反,我们有一些简单的TypeScript来递归地遍历ExpressionDefs。在将此linter检查添加到我们的CI/CD流程之后,这个linter能够捕获一些其他可能在生产中出现的bug。
在某个时候,我们考虑过将这些类型的检查添加到引擎本身,但选择了静态分析,原因有两点。首先,我们可以摆脱只需实现一次的限制,因为这不必跨平台,只在构建时评估。其次,由于它是构建时检查,工程师可以更快地发现错误,并且不必等待在测试或(更糟糕的是!)在生产或演示中出现这些错误。最后,我们了解到,只有引擎如此简单,才能采用多引擎的方法是可行的。除非我们真的必须,否则我们不想对引擎进行更改。
保持好奇
如果在我们开始这个项目时告诉我,我们将最终设计并实现我们自己的专门授权DSL,我是不会相信的。也许这是我的偏见作祟——我通常更喜欢“购买”而不是“构建”(甚至更喜欢“安装”而不是“构建”)——但我真诚地认为问题不会带我们去那里。然而,通过密切关注手头的问题,并对不同的解决方案持开放态度,我们最终提出了一些真正适合Figma的新颖的东西。
我们几乎消除了由于我们的Ruby和LiveGraph代码库之间逻辑漂移而导致的事故和错误,并通过调试器,我们为工程和支持团队提供了在他们不希望或不理解权限检查时解除阻塞的工具,以及理解和深入了解这些权限规则的能力。开发我们自己的DSL允许我们以非常基本的层面来解决问题,并为我们提供了完全的灵活性,这种灵活性今天仍然在付出。