我们长期以来一直在使用 Skew 编写我们移动渲染架构的核心部分,这是我们发明的自定义编程语言,目的是为我们的播放引擎挤出额外的性能。以下是我们如何在不中断一天开发的情况下自动将 Skew 迁移到 TypeScript 的方法。
Skew 在 Figma 早期作为一个边项目开始。当时,Skew 在 Figma 满足了一个关键需求:用对网络和移动设备的支持构建我们的原型查看器。最初作为快速启动的一种方式,最终发展成为一个完整的编译到 JavaScript 的编程语言,使得更高级的优化和更快的编译时间成为可能。但随着我们在原型查看器中积累了越来越多的 Skew 代码,我们逐渐意识到,对于新员工来说,这很难上手,不容易与我们的其余代码库集成,并且缺少 Figma 之外的开发生态系统。扩展它的痛苦逐渐超过了它最初的优势。
我们最近完成了将 Figma 所有 Skew 代码迁移到 TypeScript 的工作,这是网络行业标准语言。TypeScript 对团队来说是一个巨大的变化,并实现了:
- 通过静态导入和原生包管理,简化了与内部和外部代码的集成
- 一个庞大的开发者社区,他们构建了像 linters(代码检查工具)、bundlers(打包工具)和静态分析器这样的工具
- 现代 JavaScript 特性,如 async/await 和更灵活的类型系统
- 新开发者的无缝入职和其他团队的低摩擦
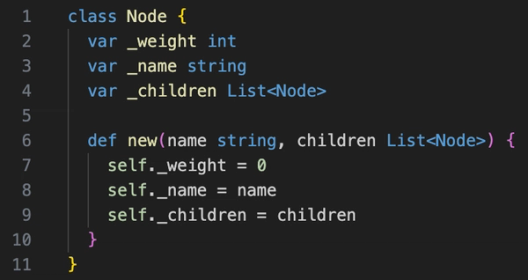
Skew 代码片段
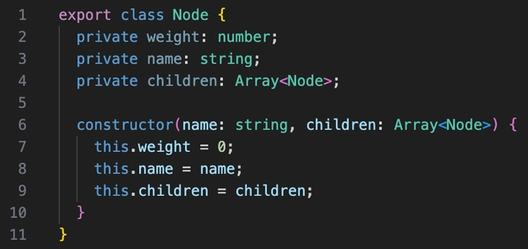
对应此 Skew 代码的 TypeScript 代码
这次迁移最近才成为可能,原因有三:
- 更多的移动浏览器开始支持 WebAssembly
- 我们用 C++ 引擎的相应组件替换了许多 Skew 引擎的核心组件,这意味着如果我们转移到 TypeScript,我们不会损失太多性能
- 团队的增长使我们能够分配资源专注于开发者体验
WebAssembly 在移动设备上获得了广泛的支持并提高了性能
当我们最初构建 Figma 的移动代码库时,移动浏览器不支持 WebAssembly,也无法以高效的方式加载大型捆绑包。这意味着我们无法使用我们的主要 C++ 引擎代码(这将需要编译成 WebAssembly)。同时,TypeScript 当时尚处于起步阶段;与 Skew 相比,它并不是显而易见的选择,Skew 拥有静态类型和更严格的类型系统这允许进行高级编译器优化。幸运的是,到 2018 年 WebAssembly 获得了移动设备的广泛支持,根据我们的测试,到 2020 年实现了可靠的移动性能。
其他性能改进赶上了 Skew 的优化
当我们最初开始使用 Skew 时,有几个关键好处:像常量折叠和去虚拟化这样的经典编译器优化,以及像生成具有真实整数操作的 JavaScript 代码这样的网络特定优化。我们越是长时间使用这些优化,就越难为离开我们培养了这么长时间的语言找到一个理由。例如,在 2020 年,基准测试表明,如果使用 TypeScript,Safari 中加载 Figma 原型的速度将慢近两倍,这是一个阻碍因素,因为 Safari(现在仍然是*)是 iOS 上允许使用的唯一浏览器引擎。
*在 iOS 17.4 中,苹果为其系统向欧盟用户开放了其他浏览器引擎。对于世界其他地区,WebKit 仍然是唯一的浏览器引擎。
WebAssembly 获得移动设备广泛支持几年后,我们用 C++ 引擎的相应组件替换了许多 Skew 引擎的核心组件。由于我们替换的组件是最热门的代码路径——比如文件加载——如果我们转移到 TypeScript,我们不会损失太多性能。这次经历给了我们信心,我们可以放弃 Skew 优化编译器的优势。
Figma 的原型和移动团队增长了
在 Figma 的早期,我们无法证明将资源转移到执行自动化迁移上是合理的,因为我们正在以尽可能快的速度构建,团队规模很小。将原型和移动团队扩展成更大的组织,使我们能够这样做。
转换代码库
当我们在 2020 年首次原型化这次迁移时,我们的基准测试显示,使用 TypeScript 的性能将慢近两倍。一旦我们看到 WebAssembly 支持足够好,并将移动引擎的核心转移到 C++,我们在公司 Maker Week 期间修复了我们的旧原型。我们展示了一个通过所有测试的工作迁移。尽管有数千个开发者体验问题和非致命类型错误,我们有一个粗略的计划,安全地迁移我们所有的 Skew 代码。
我们的目标很简单:将整个代码库转换为 TypeScript。虽然我们可以手动重写每个文件,但我们不能承受中断开发者速度以重写整个代码库的代价。更重要的是,我们想避免为我们的用户带来运行时错误和性能下降。虽然我们最终自动化了这次迁移,但这并不是一个快速的切换。与从另一种“带有类型的 JavaScript”语言迁移到 TypeScript 不同,Skew 有实际的语义差异,这让我们对立即切换到 TypeScript 感到不舒服。例如,TypeScript 只有在我们导入一个文件后才会初始化命名空间和类,这意味着如果我们以一个意外的顺序导入文件,我们可能会遇到运行时错误。相比之下,Skew 在加载时会将每个符号在运行时提供给代码库的其余部分,因此这些运行时错误不会是问题。
Evan 表示他从这次经验中吸取了一些教训,以改进网络打包工具 esbuild。
我们选择逐步推出一个由 TypeScript 生成的新代码包,这样对开发者工作流程的干扰就会最小。我们开发了一个 Skew 到 TypeScript 的转译器,它可以将 Skew 代码作为输入并输出生成的 TypeScript 代码,这是基于 Figma 前任 CTO Evan Wallace 多年前开始的工作。
第一阶段:编写 Skew,构建 Skew
我们保持了原始构建过程的完整性,开发了转译器,并将 TypeScript 代码检入 GitHub 以向开发者展示新代码库的样子。
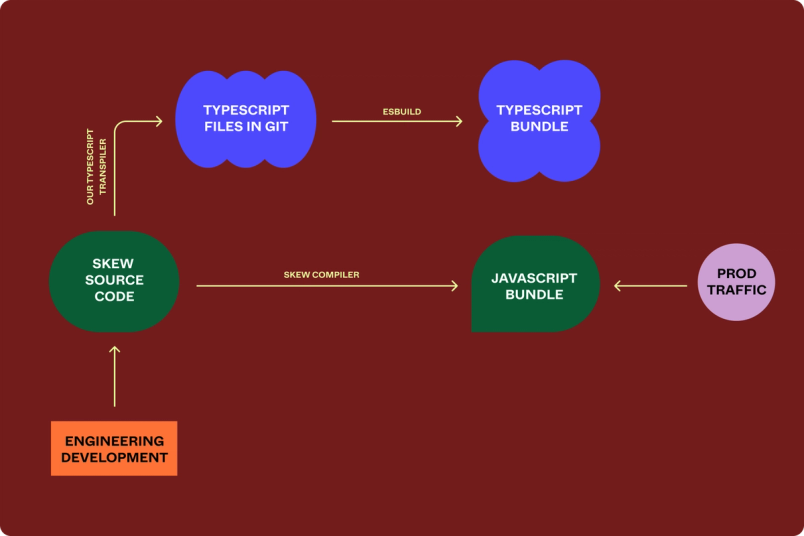
开发 TypeScript 转译器,与我们原始的 Skew 流水线并行
第二阶段:编写 Skew,构建 TypeScript
一旦我们生成了一个通过所有单元测试的 TypeScript 包,我们开始将生产流量直接构建到 TypeScript 代码库。在这个阶段,开发者仍然编写 Skew,我们的转译器将他们的代码转译成 TypeScript 并更新居住在 GitHub 中的 TypeScript 代码。此外,我们继续修复生成代码中的类型错误;即使有类型错误,TypeScript 仍然可以生成一个有效的包!
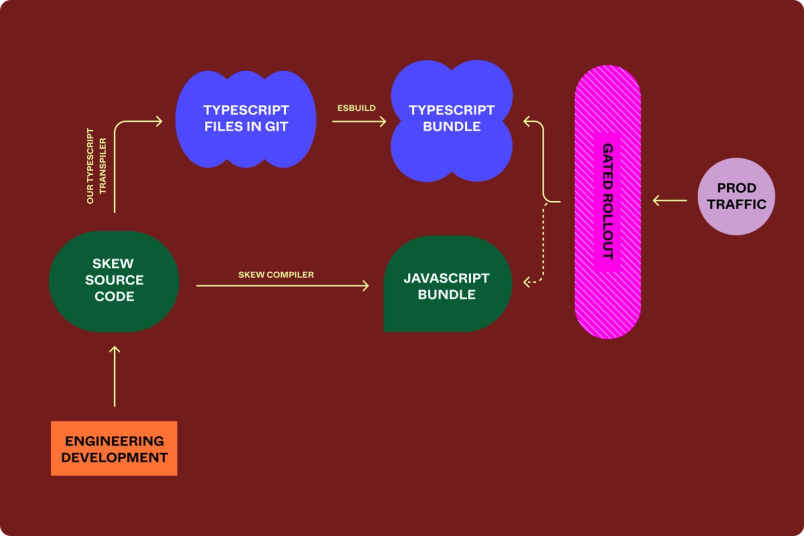
将生产流量推出到由 TypeScript 编译器从 Skew 源代码生成的 TypeScript 代码库
第三阶段:编写 TypeScript,构建 TypeScript
一旦每个人都通过了 TypeScript 构建过程,我们需要使 TypeScript 代码成为开发的主要来源。在确定了没有人合并代码的时间后,我们切断了自动生成过程,并从代码库中删除了 Skew 代码,有效地要求开发者用 TypeScript 编写代码。
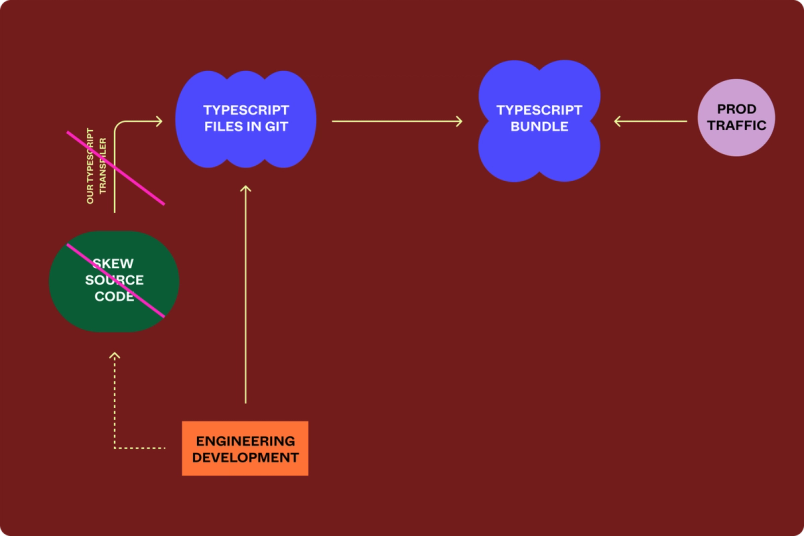
切换到使用 TypeScript 代码库作为开发者的主要来源
这是一种坚实的方法。完全控制 Skew 编译器的工作意味着我们可以用它来使第一阶段变得更容易;我们可以自由地添加和修改 Skew 编译器的部分,以满足我们的需求。我们逐步推出的策略最终也带来了好处。例如,我们在推出 TypeScript 的过程中,内部发现了一个 Smart Animate 特性的故障,因为我们正在推出 TypeScript。我们有门控的方法允许我们快速关闭推出,修复故障,并重新思考我们推出计划的继续方式。
我们还就切换到使用 TypeScript 进行了充分的预告。在一个周五晚上,我们合并了所有必要的更改,以去除自动生成过程,并使我们所有的持续集成作业直接运行 TypeScript 文件。
关于我们的转译器工作的说明
如果你不知道编译器是如何工作的,这里是一个高层次的概览:编译器本身由前端和后端组成。前端负责解析和理解输入代码并执行类型检查和语法检查等操作。前端然后将此代码转换为中间表示(IR),这是一个完全捕获原始输入代码的语义和逻辑的数据结构,但结构化的方式是,我们不需要担心重新解析代码。
编译器的后端负责将此 IR 转换为不同语言。在像 C 这样的语言中,一个后端通常会生成汇编/机器代码,而在 Skew 编译器中,后端生成了混淆和压缩的 JavaScript。
转译器是一种特殊类型的编译器,其后端产生人类可读的代码,而不是混淆的机器代码;在我们的情况下,后端需要采用 Skew IR 并产生人类可读的 TypeScript。
编写 转译器 的过程起初相对简单:我们从 JavaScript 后端借鉴了很多灵感,并根据我们在 IR 中遇到的信息生成适当的代码。在我们接近尾声时遇到了几个更难以追踪和处理的问题:
- 数组解构的性能问题: 放弃 JavaScript 数组解构带来了高达 25% 的性能提升。
- Skew 的“去虚拟化”优化: 我们在推出过程中采取了额外的步骤,以确保去虚拟化——一种编译器优化——不会破坏我们代码库的行为。
- TypeScript 中的初始化顺序很重要: 在 TypeScript 中,符号的顺序很重要,与 Skew 相反,所以我们的转译器需要生成尊重这种顺序的代码。
数组解构的性能问题
当我们在一些样本原型中调查 Skew 和 TypeScript 之间的离线性能差异时,我们注意到 TypeScript 中的帧率较低。经过大量调查,我们发现根本原因是数组解构——事实证明,在 JavaScript 中这是相当慢的。
要完成像 const [a, b] = function_that_returns_an_array() 这样的操作,JavaScript 会构建一个迭代器,该迭代器遍历数组,而不是直接从数组索引,这更慢。我们这样做是为了从 JavaScript 的 arguments 关键字检索参数,导致某些测试案例的性能变慢。解决方案很简单:我们生成直接索引参数数组的代码而不是解构,并提高了每帧延迟高达 25%!
Skew 的“去虚拟化”优化
查看 这篇关于去虚拟化的文章 了解更多信息。
另一个问题是 TypeScript 和 Skew 处理类方法的方式之间的分歧,这导致了我们在推出过程中 Smart Animate 的故障。Skew 编译器做了一些称为 去虚拟化 的事情,这是一种在某些条件下将函数从类中提取出来作为性能优化,并将其提升为全局函数:
myObject.myFunc(a, b)
// 变成...
myFunc(myObject, a, b)
这种优化在 Skew 中发生,但不在 TypeScript 中。Smart Animate 的故障发生是因为 myObject 是 null,我们看到了不同的行为——去虚拟化的调用可以正常运行,但非去虚拟化的调用会导致 null 访问异常。这让我们担心是否有其他具有相同问题的调用站点。
为了缓解我们的担忧,我们在所有将参与去虚拟化的函数中添加了日志记录,以查看这个问题是否曾经在生产中发生过。在短时间启用此日志记录后,我们分析了我们的日志并修复了所有有问题的调用站点,使我们对 TypeScript 代码的鲁棒性更有信心。
TypeScript 中的初始化顺序很重要
我们遇到的第三个问题是每种语言如何尊重初始化顺序。在 Skew 中,你可以在代码的任何地方声明变量、类和命名空间以及函数定义,它不会关心它们声明的顺序。然而,在 TypeScript 中,它确实很重要,是否首先初始化全局变量或类定义;在类定义之前初始化静态类变量是编译时错误。
我们最初的转译器版本通过生成不使用命名空间的 TypeScript 代码来解决这个问题,有效地将每个函数都展平到全局作用域。这保持了与 Skew 类似的行为,但生成的代码不太易读。我们重新设计了转译器的部分,以正确的顺序发出 TypeScript 代码,以提高清晰度和准确性,并为可读性添加了回 TypeScript 命名空间。
尽管存在这些挑战,我们最终构建了一个通过所有单元测试并产生与 Skew 性能相匹配的编译 TypeScript 代码的转译器。我们选择手动修复一些小问题,要么在 Skew 源代码中,要么一旦我们切换到 TypeScript——而不是编写转译器的新修改来修复它们。虽然所有修复都保留在转译器中是理想的,但现实是,有些更改不值得自动化,我们可以通过这种方式更快地修复一些问题。
案例研究:使用源代码映射保持开发者的幸福感
在整个过程中,开发者的生产力始终是首要考虑的。我们希望尽可能地使迁移到 TypeScript 的过程变得容易,这意味着尽一切可能避免停机并创建无缝的调试体验。
网络开发人员主要使用现代网络浏览器提供的调试器进行调试;你在源代码中设置一个 断点,当代码到达这一点时,浏览器将暂停,开发者可以检查浏览器的 JavaScript 引擎的状态。在我们的情况下,开发者会想要在 Skew 或 TypeScript 中(取决于我们在项目的哪个阶段)设置断点。
但浏览器本身只能理解 JavaScript,而断点实际上是在 Skew 或 TypeScript 中设置的。鉴于源代码中的断点,浏览器如何知道在编译后的 JavaScript 捆绑包中应该在哪里停止呢?进入:源代码映射,浏览器知道如何将编译后的代码链接回源代码的方式。让我们看一个简单的 Skew 代码示例:
def helper() {
return [1, 3, 4, 5];
}
def myFunc(myInt int) int {
var arrayOfInts List<int> = helper();
return arrayOfInts[0] + 1;
}
这段代码可能会被编译并压缩成以下 JavaScript:
function c(){return [1,3,4,5];}function myFunc(a){let b=c();return b[0]+1;}
这种语法很难阅读。源代码映射将生成的 JavaScript 的部分映射回源代码的特定部分(在我们的情况下,是 Skew)。源代码映射之间的映射将显示:
helper → cmyInt → aarrayOfInts → b
查看 这篇关于源代码映射的文章 以获取有关生成、理解和调试源代码映射的更多技术细节。
一个源代码映射通常具有 .map 文件扩展名。一个源代码映射文件将与最终的 JavaScript 捆绑包相关联,以便在给定 JavaScript 文件中的代码位置时,我们的 JavaScript 捆绑包的源代码映射将告诉我们:
- 这段 JavaScript 来自哪个 Skew 文件
- 与这段 JavaScript 对应的 Skew 文件中的代码位置
每当开发者在 Skew 中设置调试器断点时,浏览器简单地反向这个源代码映射,查找这个 Skew 行对应的 JavaScript 的部分,并在那里设置断点。
以下是我们如何将此应用于我们的 TypeScript 迁移:我们最初的基础设施生成了 Skew 到 JavaScript 源代码映射,我们用于调试。然而,在我们的迁移的第二阶段,我们的捆绑包生成流水线完全不同,先生成 TypeScript,然后使用 esbuild 打包。如果我们试图使用原始基础设施中的相同源代码映射,我们将得到 JavaScript 和 Skew 代码之间的不正确映射,开发者将无法在这个阶段调试他们的代码。
我们需要使用我们的新构建过程生成新的源代码映射。这涉及以下三部分工作,如下所示:
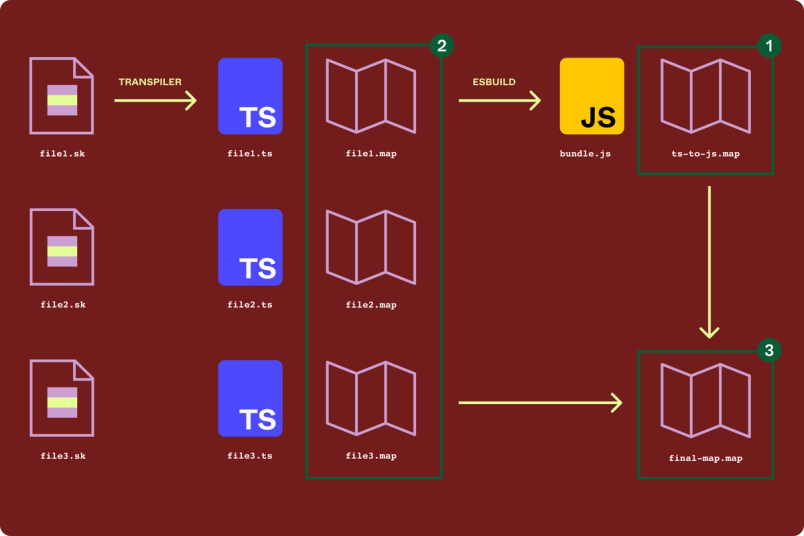
使用我们的新构建过程生成新源代码映射的图表
步骤 1:生成 TypeScript → JavaScript 源代码映射 ts-to-js.map。esbuild 可以在生成 JavaScript 捆绑包时自动生成这个映射。
步骤 2:为每个 Skew 源文件生成 Skew → TypeScript 源代码映射。如果我们将文件命名为 file.sk,转译器将把源代码映射命名为 file.map。通过模仿 Skew → JavaScript 后端的 Skew 编译器创建源代码映射的方式,我们在 TypeScript 转译器中实现了这一点。
步骤 3:将这些源代码映射组合在一起,以产生从 Skew 到 JavaScript 的映射。为此,我们在构建过程中实现了以下逻辑:
对于 ts-to-js.map 中的每个条目 E:
- 确定此条目映射到哪个 TypeScript 文件,并打开其源代码映射
fileX.map。 - 在
fileX.map中查找E中的 TypeScript 代码位置,以获得相应 Skew 文件fileX.sk中的代码位置。 - 将这作为新条目添加到我们的最终源代码映射中:来自
E的 JavaScript 代码位置与 Skew 代码位置相结合。
有了我们的最终源代码映射,我们现在可以将新的 JavaScript 捆绑包映射到 Skew,而不干扰开发者体验。
案例研究:条件编译
在 Skew 中,顶层的“if”语句允许有条件的代码编译,我们通过传递给 Skew 编译器的“defines”选项中的编译时常量来指定条件。我们可以使用它来定义给定代码库的多个构建目标——捆绑不同部分的代码——这样我们可以有相同的代码库的不同捆绑包,以不同的方式使用相同的代码库。例如,一个捆绑包变体可以是实际部署给用户的实际捆绑包,另一个可能只用于单元测试。这允许我们指定在调试或发布构建中使用不同实现的某些函数或类。
为了更明确,以下 Skew 代码为 TEST 构建定义了不同的实现:
if BUILD == "TEST" {
class HTTPRequest {
def send(body string) HTTPResponse {
# 测试专用实现...
}
def testOnlyFunction {
console.log("hi!")
}
}
} else {
class HTTPRequest {
def send(body string) HTTPResponse {
# 真实实现...
}
}
}
当向 Skew 编译器传递 BUILD: "TEST" 定义时,这将编译成以下 JavaScript:
function HTTPRequest() {}
HTTPRequest.prototype.send = function(body) {
// 测试专用实现...
}
HTTPRequest.prototype.testOnlyFunction = function(body) {
console.log("hi!")
}
然而,条件编译不是 TypeScript 的一部分。相反,我们必须在类型检查后的构建步骤中执行条件编译,作为使用 esbuild 的“defines”和死代码消除特性的捆绑步骤的一部分。这意味着 defines 不再能影响类型检查,这意味着像上面示例中那样只在 BUILD: "TEST" 构建中定义方法 testOnlyFunction 的代码不能存在于 TypeScript 中。
我们通过将上述 Skew 代码转换为以下 TypeScript 代码来解决这个问题:
// 在 esbuild 步骤中定义的值
declare const BUILD: string
class HTTPRequest {
send(body: string): HTTPResponse {
if (BUILD == "TEST") {
// 测试专用实现...
} else {
// 真实实现...
}
}
testOnlyFunction() { if (BUILD == "TEST") {
console.log("hi!")
} else {
throw new Error("Unexpected call to test-only function")
}
}
}
这编译成与原始 Skew 代码直接编译的相同 JavaScript 代码:
function HTTPRequest() {}
HTTPRequest.prototype.send = function(body) {
// 测试专用实现...
}
HTTPRequest.prototype.testOnlyFunction = function(body) {
console.log("hi!")
}
不幸的是,我们的最终捆绑包现在稍微大了一点。一些原本只在一种编译模式下可用的符号现在在所有模式下都存在了。例如,我们只在构建模式 BUILD 设置为 "TEST" 时使用 testOnlyFunction,但在这次更改后,该函数始终在最终捆绑包中存在。在我们的测试中,我们发现捆绑包大小的这种增加是可以接受的。我们仍然可以通过 tree-shaking 移除未导出的顶层符号。
在 TypeScript 中开启原型开发新时代
通过将所有 Skew 代码迁移到 TypeScript,我们现代化了 Figma 的一个关键代码库。我们不仅为它与内部和外部代码的更轻松集成铺平了道路,开发者也因之而工作得更高效。最初用 Skew 编写代码库是一个好决定,考虑到当时 Figma 的需求和能力。然而,技术不断进步,我们学会了永远不要怀疑它们成熟的速率。尽管 TypeScript 当时可能不是正确的选择,但现在绝对是。
我们希望获得迁移到 TypeScript 的所有好处,所以我们的工作不会就此结束。我们正在探索许多未来的可能性:与我们代码库的其余部分集成,大大简化的包管理,以及直接使用活跃的 TypeScript 生态系统的特性。我们对 TypeScript 的不同方面——如导入解析、模块系统和 JavaScript 代码生成——了解了很多,我们迫不及待地想把这些知识运用到实践中。